
数据对于我们的产品而言至关重要。数据分析帮助我们为使用我们服务的用户提供了流畅的体验。它也让工程师、产品经理、数据分析师、数据科学家可以在了解情况后作出明智的决定。数据分析影响了 App 的每一个界面:在主界面上显示什么,产品以什么顺序显示,向用户显示哪些相关的信息,什么妨碍了用户乘车或注册,诸如此类。
如此大的用户群体,如此广泛的特性,还要覆盖所有的地理区域,这是一个很复杂的问题。而且,我们的 App 一直在推出新产品,这就要求底层的技术也要有足够的灵活性来支持这种发展。
数据是实现这种发展的最基本工具。本文将聚焦乘客数据:我们如何收集和处理以及这些数据具体如何影响了乘客端 App 的改进。
乘客数据包含了乘客与 Uber 乘客端 App 的所有交互。其中每天都会有来自 Uber 在线系统的数十亿个事件,这些事件转换成了数百张 Apache Hive 表,为乘客端 App 的不同应用场景提供支持。
下面是可以利用乘客数据分析的主要问题领域:
- 增加漏斗转化
- 提高用户参与度
- 个性化
- 用户沟通
乘客数据有多个来源,但最基本的一个是获取用户与 App 的交互过程。用户交互是通过移动端的事件日志获取的。下面是日志架构设计的一些关键原则:
- 日志标准化
- 跨平台一致性(iOS、Android、Web)
- 尊重用户隐私设置
- 优化网络使用
- 可靠但不降低用户体验
日志标准化
有一个标准的日志记录过程很重要,因为数以百计的工程师在增加或编辑事件。从客户端收集的日志有的是平台化的(像用户与 UI 元素的交互事件、内容曝光次数等),有的是由开发人员手动添加的。
我们将一组元数据进行了标准化,作为默认的公共负载随每个事件发送,如位置、App 版本、设备、昵称等。这对于后台指标计算至关重要。
此外,为了确保所有事件跨所有平台都能保持一致,并且有标准的元数据,我们定义了 Thrift 结构,事件模型需要实现这个结构来定义其有效负载。Thrift 模式包含一个枚举(表示在不同平台上的事件 ID)和一个有效负载结构(定义了事件注册时与之关联的所有数据),最后还有一个事件类型。
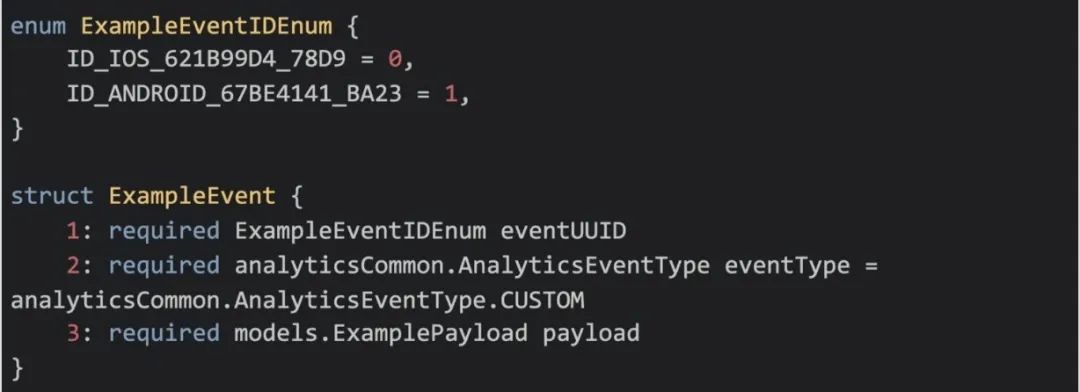 示例:Thrift 模式中分析事件的标准化定义
示例:Thrift 模式中分析事件的标准化定义
这些日志通过管道进入 Unified Reporter,这是客户端里的一个框架,用于摄取客户端产生的所有消息。Unified Reporter 会将消息存储在队列中,对它们进行聚合,然后通过网络每隔几秒分批次地发送给后台的 Event Processor。
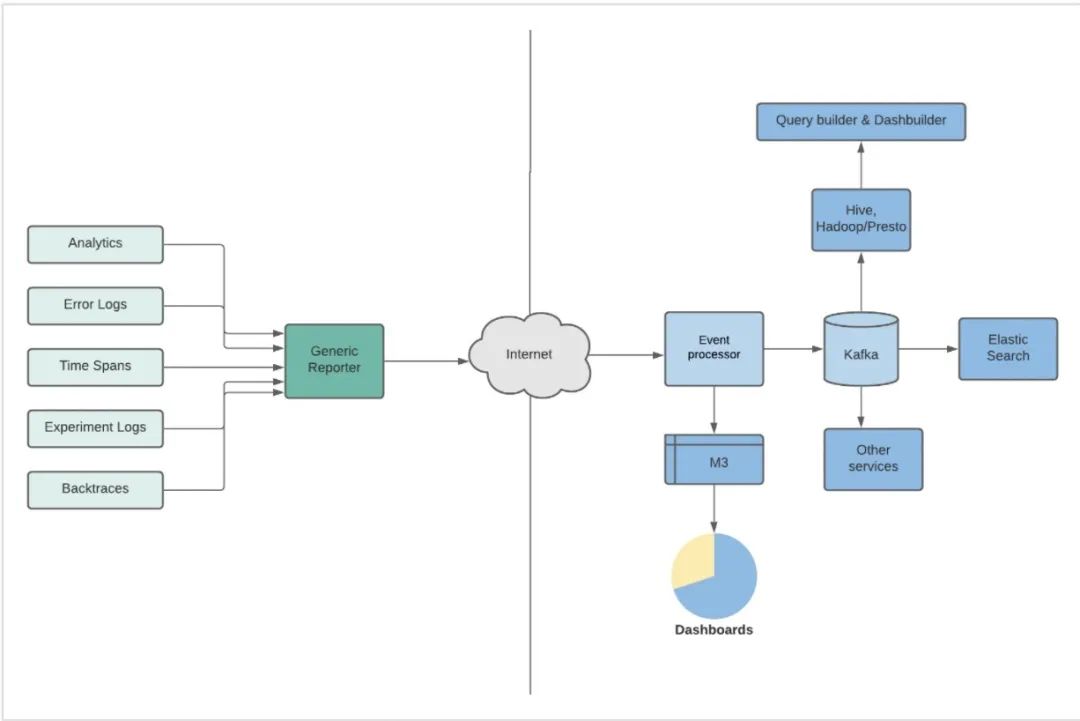 图 1 事件被记录到仪表盘和数据集的过程
图 1 事件被记录到仪表盘和数据集的过程
事件一直在增加或变化——每天处理的事件有几百种类型。其他日益严重的问题还有:跨不同操作系统(Android 和 iOS)的日志平台化、可发现性以及如何保持良好的信噪比。Event Manager 门户负责管理这些事件的元数据,并为事件选择合适的接收器。
Event Processor 根据接收到的元数据确定如何处理事件以及进一步传播。此外,如果事件的元数据和映射不可用,Event Processor 就会阻挡该事件,不再向下游传播。这是为了提升信噪比。
伴随用户交互,我们要记录 App 向用户展示了什么内容,这很重要。我们是通过在后台记录服务层的数据来实现的。后台日志记录处理的数据更多,有些是移动端没有的,有些是移动端处理不过来的。由移动端或其他系统发起的每次后端调用都会有数据记录。每条记录都有一个”join“键,通过它可以关联到移动端交互。这项设计可以保证移动端带宽得到有效使用。
我们把从移动端和服务层收集到的数据进行结构化,并作为离线数据集进行复制。离线数据集帮助我们识别上文提到的问题,并评估为解决这些问题所开发的解决方案有多成功。
原始的大型离线数据集真得很难处理。我们对原始数据进行扩充并建模,形成分层表。在扩充过程中,我们把不同的数据集连接在一起,让数据更有意义。建模形成的表可以带来以下几个方面的好处:
- 节省资源:仅计算一次并存储。其他任何人都不需要在原始的大型数据集上运行查询。
- 标准化定义:业务逻辑和指标定义都在 ETL 中(提取、转化、加载),不需要消费者操心。如果把这项工作留给消费者,那么每个团队可能会做不同的计算。
- 数据质量:可以保证适当的检查对比,因为逻辑都在一个地方,数据很容易检验。
- 所有权:随着数据演化,数据所有者可以确保表能够适用于新特性。
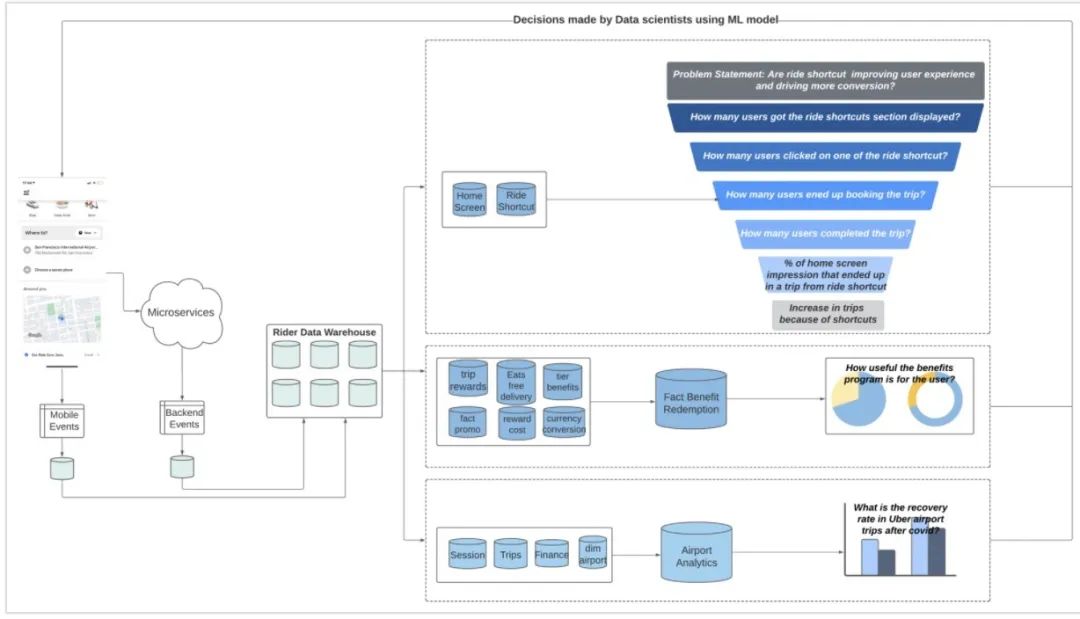 图 2 各种离线数据处理场景
图 2 各种离线数据处理场景
让我们考虑一下下面这个问题描述:
快捷乘车改善了乘客体验,促成了更多转化(出行)吗?
我们从保存了用户交互和主界面内容的基础事实表中筛选出与“快捷乘车”相关的信息,并通过与其他多个数据集集成对它进行扩充,进而实现漏斗分析:
- 有多少用户显示了快捷乘车区域?
- 有多少用户点击了其中的一个快捷方式?
- 有多少用户(来自 #2)最终预定了出行?
- 有多少用户(来自 #3)完成了出行?
- 通过快捷乘车流程和普通流程完成出行的主界面曝光比是多少?
- 快捷乘车对于出行预定的总体效果是什么?
- 奖励计划对于乘客的作用有多大?
为了找出这个问题的答案,表中应该包含如下数据:
- 选择 / 兑换的奖励
- 未使用或过期的奖励
- 乘客如何赢得奖励?
还有其他一些有趣的数据点,如:
- 奖励计划增加了 App 的总体使用量吗?
- 支出是否与这项计划的预算相符?
奖励可以通过 Eats、Rides 和其他 Uber 应用的不同功能进行兑换。一旦用户在移动端选择了一项奖励,就会触发中心化的奖励后端服务。它会处理奖励信息,将每个奖励选择行为记录为交易数据。有些奖励是自动应用的,但有些是促销驱动的。促销驱动的奖励兑换是在另一个促销系统中处理的。此外,这个系统的构建让运营或产品团队能够根据需要轻松添加新的奖励。我们构建工具来获取奖励元数据,这些元数据反过来又流向另一个系统。有个 ETL 作业会读取流经不同系统的数据,生成一个奖励兑换数据模型。此外,这些数据还能帮助财务团队获取 Uber 在奖励计划中的开销,让人们对这个产品有一个良好的理解。
- 在 COVID-19 之后,Uber 航空出行的恢复率是多少?
航空出行的不同指标是从上游多个表收集的,包括出行、会议、理财、航空出行及其他乘客表等不同的领域。来自不同领域的数据会被聚合,然后在一组维度下计算成指标,存储到一个表中。将最新数据与经过聚合的历史数据进行比较,可以帮助我们找到上面这个问题的答案。
此外,航空出行数据还被用于绘制机场接机的落地数据热图,计算机场总接机量、总预定量等。所有这些数据都有助于我们业务的发展,还有助于业务本地化,满足不同地域的不同需求。
数据可以为我们提供业务决策的依据。因此,保证数据的完整性和质量变得非常重要。在乘客端 App 的架构中,为了保证数据质量,我们在多个层面做了数项检查。
在产生事件的时候,我们引入了测试框架进行构建时测试、模式和语义检查。这些框架会检查是否有分析事件被触发,有效负载、顺序是否符合预期。
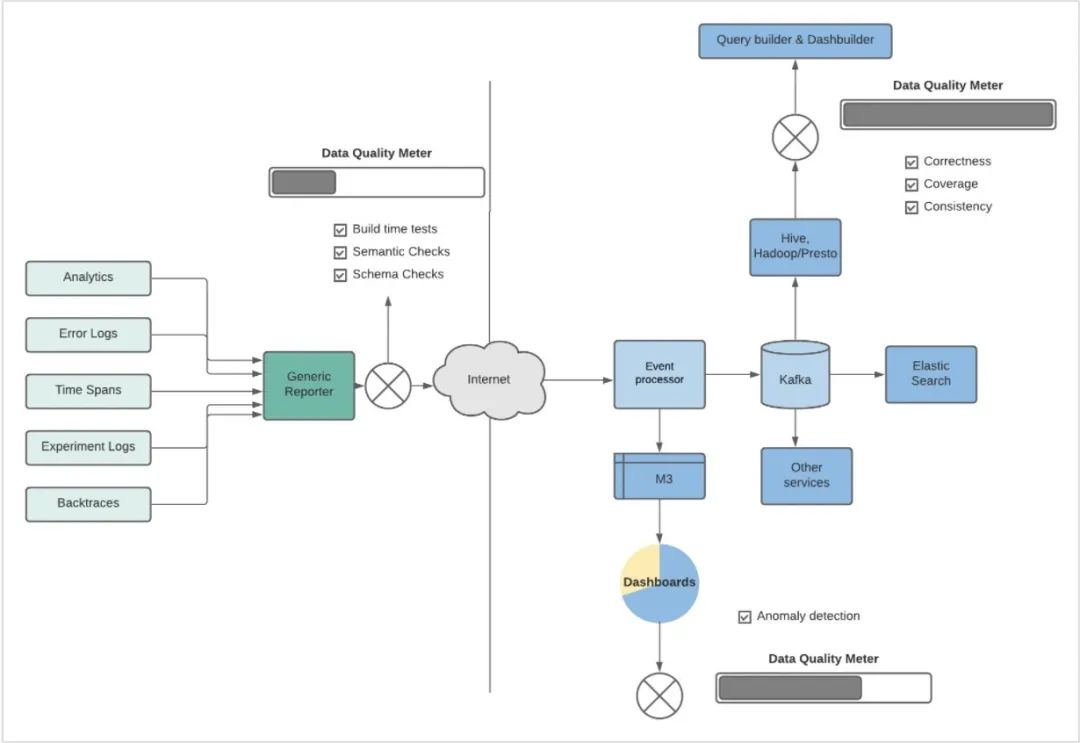 图 3 数据流数据质量检查
图 3 数据流数据质量检查
一旦事件到达离线存储并处理,异常检测功能就可以保证数据被记录并按照预期流转。系统会监控事件量,如果突然出现下降或峰值,就给所有者发送告警信息。这种监控有助于捕捉差异,防止出现中断而没有发现。在离线建模的表中,测试框架被用于确保数据的正确性、覆盖率以及各表之间的一致性。每次管道运行都会触发配置好的测试,保证产生的任何数据都能满足质量 SLA(服务水平协议)。
根据上面这些从数据收集机制中了解到的东西,我们对乘客端 App 做了一些更改,下面是几个具体的例子:
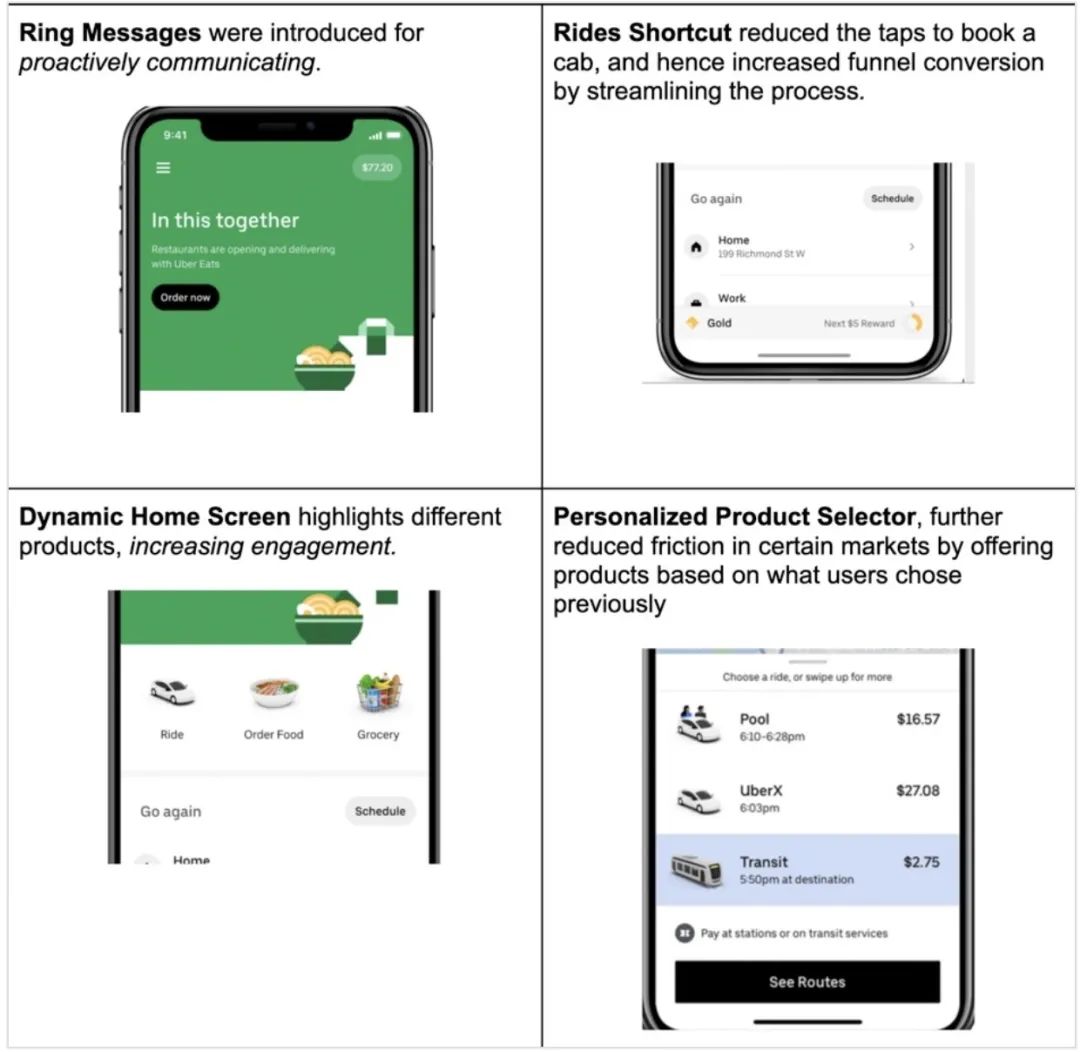 并非所有特性在所有市场中都可用
并非所有特性在所有市场中都可用
高质量的数据是推动应用程序演进的强大工具。不说别的,它可以帮助我们改善用户体验,这反过来又增加了用户粘度,促进了用户增长。此外,在添加新特性的时候,数据可以告诉我们什么最适合用户,保证更改不会导致用户体验下降。我们深刻理解数据的重要性,我们一直在提升 Uber 的数据文化。
英文原文:https://eng.uber.com/how-data-shapes-the-uber-rider-app/
更多阅读:
