

张院士从技术演变的大趋势引入,提出了 Real2Sim2Real 现实-仿真-现实 (RSR)的概念,并介绍了其在智能机器人和自动驾驶这两个领域的应用前景做了深入探讨。

他首先介绍了清华大学智能产业研究院(AIR),其使命是用人工智能技术赋能产业推动社会进步,定位面向第四次工业革命的国际化、智能化、产业化研究机构,AIR有三个战略目标:一是培养技术领军人才,具有国际视野的CTO和系统化思维的架构师,二是推动关键核心技术突破,三是打造产业影响力。

目前AIR已经有近200位教授,研究者和学生,1/3在从事自动驾驶和机器人相关的研究和产业化。科研人员中不仅仅有很深学术造诣的企业创新人才,也有很多产业背景的学术人才,并且和很多产业有了深度的合作。

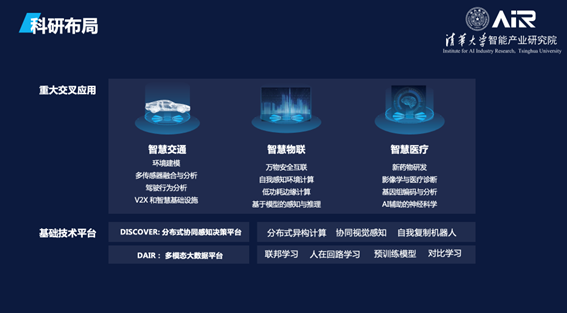
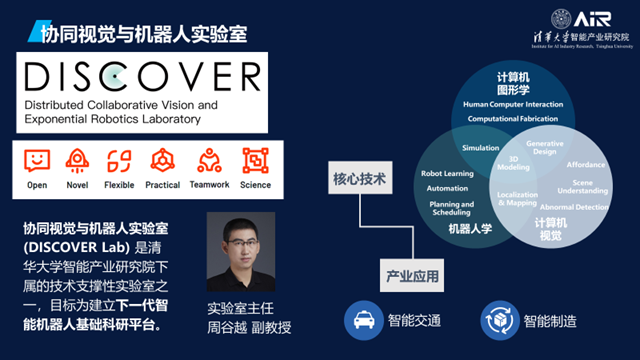
基于未来的重大产业机遇和发展需要,AIR选择了智慧交通(AI+Transportation)、智慧物联(AI+IoT)、智慧医疗(AI+Life Science)三个重点研发方向。同时AIR还构建了两个基础研究平台,分别是DISCOVER(协同视觉与机器人实验室)和DAIR(大数据智能实验室),来整体支撑三大方向的研究。
IT技术的发展有三个大的趋势,数字内容从1.0时代逐步迈入3.0时代;人工智能从符号推理、深度学习,走向知识+数据驱动的3.0;产业从信息化、互联网+、走向智能+3.0时代。

数字3.0时代是信息智能+物理智能+生物智能的时代。物理世界的数字化,我们也将其称之为“互联网的物理化”,即汽车、公路、交通、工厂、电网、机器,乃至所有移动设备、家庭、城市都在数字化。数据指数增长,比如一辆无人车每天产生的数据量大约为5T,相比于数据主要提供给人员辅助决策的1.0和2.0时代,数字化3.0时期99%以上数据是M2M和机器决策。
生物世界的数字化,即我们的大脑、器官、DNA、蛋白质、细胞、分子…都在数字化。生物芯片、组学技术、和高通量实验产生了天文级的数据。从虚拟、宏观到微观,整个数字信息世界、物理世界和生物世界正在走向融合。

在智能机器人和自动驾驶两个领域,最大的特点就是研发成本特别高,而产业化产品速度又很低。比如在测试阶段花费的钱就高达几百亿,无人驾驶又需要做大量的路测,所以产品化速度又非常慢。如何实现虚实映射,不管是仿真还是模拟,来降低研发成本,来实现快速迭代,这就是接下来要谈的主要内容。

当下,全球市值超过万亿美金的企业如Alphabet、Tesla、Google、Amazon、Apple都在关注智能机器人和无人驾驶这两个产业。在过去5年左右甚至更长的时间里,这两个产业也是最活跃的VC投资方向,投资资金将近1000亿美金。国内的科技巨头企业如华为、小米、大疆等都在关注这两个产业。

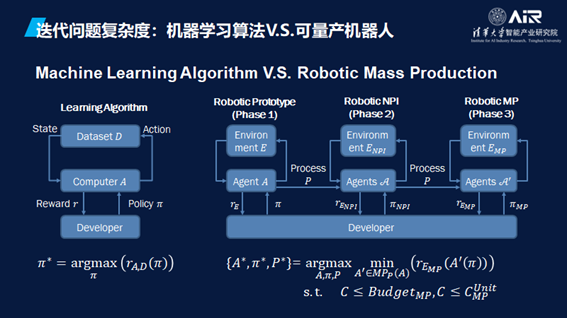
研发成本高在于迭代成本高。以周谷越教授提供的例子来讲,对比左边单网络模型的机器学习算法,与右面展示的机器人从原型到量产的过程。以四旋翼的视觉导航机器人为例,在第一个原型机阶段就有十倍的成本差距。后续的迭代阶段,问题的复杂度与成本差距的数量级逐步上升。
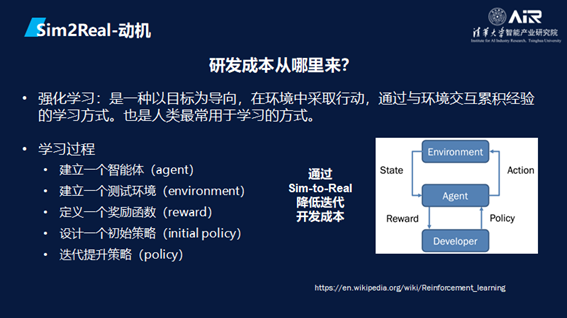
强化学习是一种以目标为导向,在环境中采取行动,通过与环境交互累积经验的学习方式,这也是人类最常用的学习、研发的方式。
学习过程包括首先建立一个智能体,然后建立一个测试环境,定义一个奖励函数,设计一个初始策略,不断迭代然后提升策略。那么问题就在于能否建立一个虚拟的环境,并在里面快速迭代,将这些成果运用到现实世界,而Sim2Real技术的出现,将有机会实现降低迭代开发成本的效果。
近年来,深度学习让Robot Learning带来了跨越式发展,使得Sim2Real技术有了应用于真实世界的机会。因为一些领域的真实数据通常来说很难获取,比如无人驾驶,而仿真技术就可以产生很多数据,这些虚拟数据就能助力模型的迭代。

第二个趋势是将任务变得更复杂和通用。从某个指定机器人到某品类机器人再到跨品类机器人。在这其中有两种不同的路径,第一种是泛化,另外一种则是更深度,要解决具体问题。

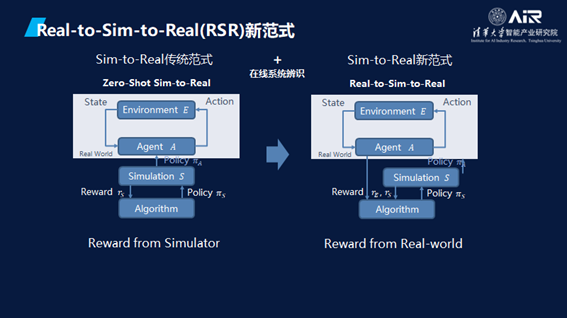
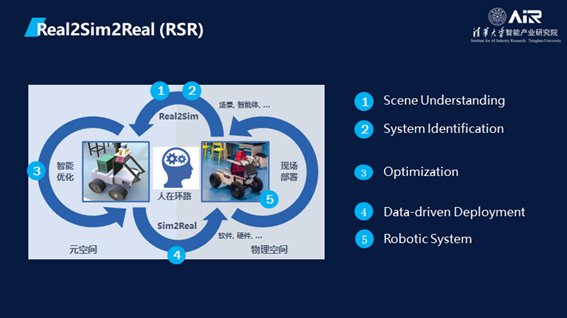
因此,AIR提出了Real2Sim2Real (RSR)的新范式 — 打造元空间和物理世界的闭环。
接着,张院士介绍了一些AIR的协同视觉与机器人实验室(DISCOVER Lab)做的工作。

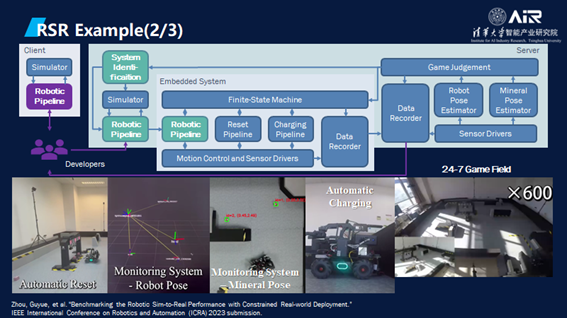
AI算法是经过了一个组合的策略训练,比如定位导航部分是有系统参数辨识来完成;控制部分是通过搜索控制器的参数来完成的;抓取部分是通过强化学习完成的。可以说我们实现了全球首个机器人移动操作任务的RSR。

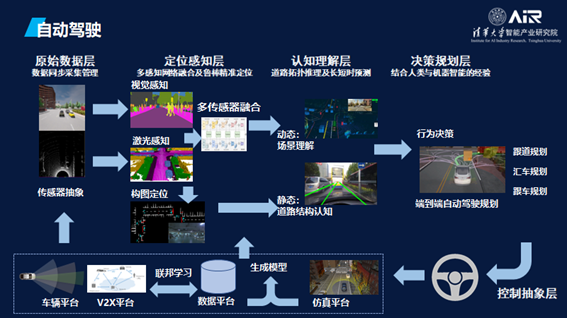
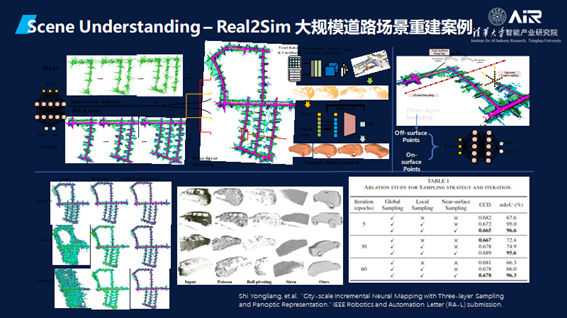
RSR首先要有场景的理解(Scene Understanding),然后需要理解系统,将目标放入虚拟空间之后再进行各种各样的仿真和优化,经过数据驱动的部署之后再回到机器系统。
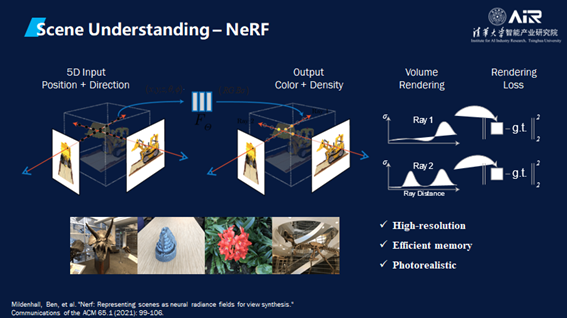
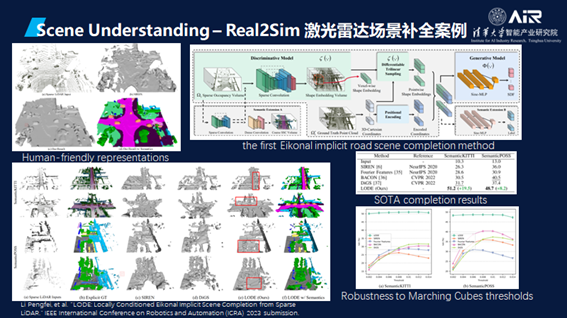
最重要第一步是Scene Understanding,不仅仅是了解几何,还要了解语意。这个论文结果重点在于它可以产生更真实的数据去仿真物理现象。
相关的一个工作还有Scene Graph,将真实世界分解成许多不同的情况,例如开车时周围移动的车,路边停放的车或者物体,红绿灯,不同的路面标识等。
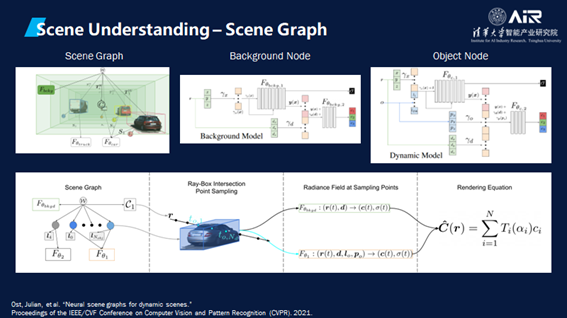
机器首先要做的事就是理解场景。接下来这一篇AIR刚投稿的论文就解释了如何把不同场景提取出来。其中的亮点在于定义了一个四元组匹配策略,基于布局四元组定制的一个度量的一致性损失。另外也周谷越副教授团队还提出了一个创新算法,可以用到完全监督的设置中去。

其次,机器人还需要去理解操作对象。以下的这篇也是AIR刚投到CVPR的论文,主要在将如何仅仅使用重建目标的自监督时间关键点检测器。
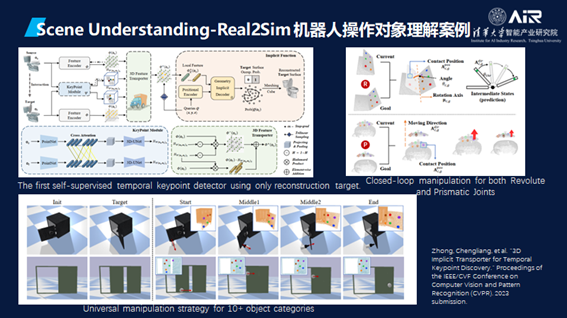
模型和真实世界需要完美匹配离不开部署。这里提供了两种方法去结合仿真数据和真实数据。一个是目前混合的离线-在线的强化学习,另外一个是通过Koopman Operator部署MPC策略。论文已分别在NeurIPS与Robotics and Automation Letters上发表。

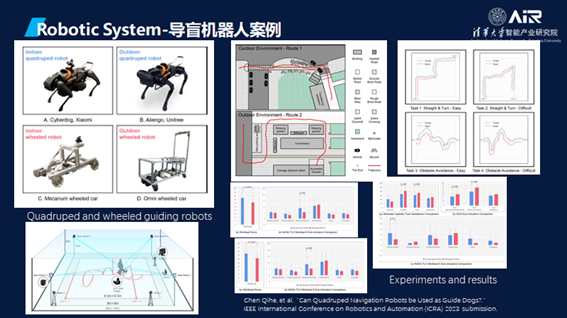
接下来,是两个在机器人上应用的案例。在人机交互方面,探索了四足仿生犬与轮式机器人在导盲领域的应用,通过量化的行为与心理指标,验证了四足机器犬并非理想的导盲犬的替代品,这类研究在产品落地的过程中起到重要的作用,相关论文已投稿至ICRA。
在城市无人机的定位导航项目中,系统算法被成功执行到真实机器人上,相关论文已投稿至CVPR。

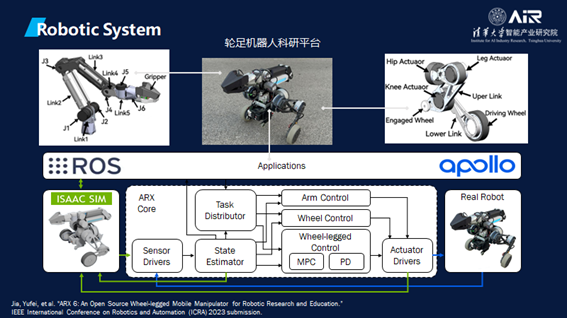
此外,DISCOVER实验室还建立了一个轮足机器人科研平台,从ROS到Apllo的一个开源平台。
在技术层面,作为自动驾驶安全的基础,感知是首要关注的问题。计算机和人类一样,需要在驾驶过程中动态地对周边的三维场景进行时空建模。在不同的场景下,借助不同模态的数据,算法不仅要完成对于车辆、行人等目标的检测,还需实现对于路标、交通信号等语义的理解。
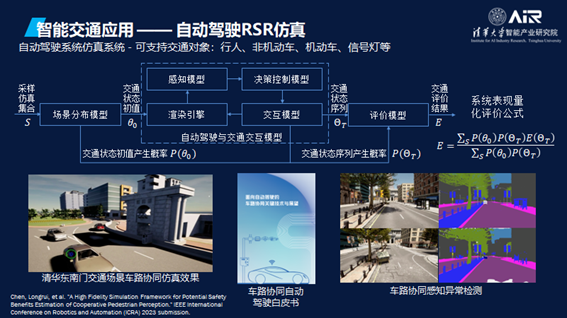
这是最近做的一个工作,自动驾驶的仿真中可以支持各种各样的对象,包括人、机动车与非机动车、信号灯以及各种道路状况。
在Ost,Julian的这篇论文中,用算法提取了场景和运动的车辆进行了仿真模拟,在模拟器中可以做各种各样的测试,即使撞车也没有关系,这是在真实世界中难以做到的,可以产生更多数据。

驾驶车辆需要一系列的传感器来共同完成感知任务,不同传感器各司其职:激光雷达可以直接采集距离信息,实现三维环境匹配及盲点探测;视觉相机可以采集的色彩和外形等细节信息,实现物体的快速辨认和车道识别;毫米波雷达则可以进行速度和距离的测量,发出碰撞预警并进行紧急制动。
理论上,多传感器的融合可以获取到比人眼更多、更高维度的数据,可以感知到肉眼不可见的物体,这是现阶段自动驾驶中唯一确定的机器可以超越人的环节,也是影响自动驾驶安全提升的决定性因素。使用单一的视觉传感器容易受到光照和天气等因素影响,因此导致自动驾驶系统产生误判的例子屡见不鲜。在自动驾驶夜间感知上,如果用纯视觉如何将灰度的信息和深度信息结合起来。

用RSR来仿真车路协同评价体系,很重要的一点是我们不仅模拟了车、路灯,还模拟了人。无人驾驶最大的事故就是车撞倒人,在这个模拟中行人的行为也被放了进去。


更多阅读:
