
近日SuperCLUE发布了最新的中文大模型10月榜单,GPT4继续霸榜位列第1,vivo自研大模型vivoLM以70.74的成绩位列第4,在国内大模型中排行第1。
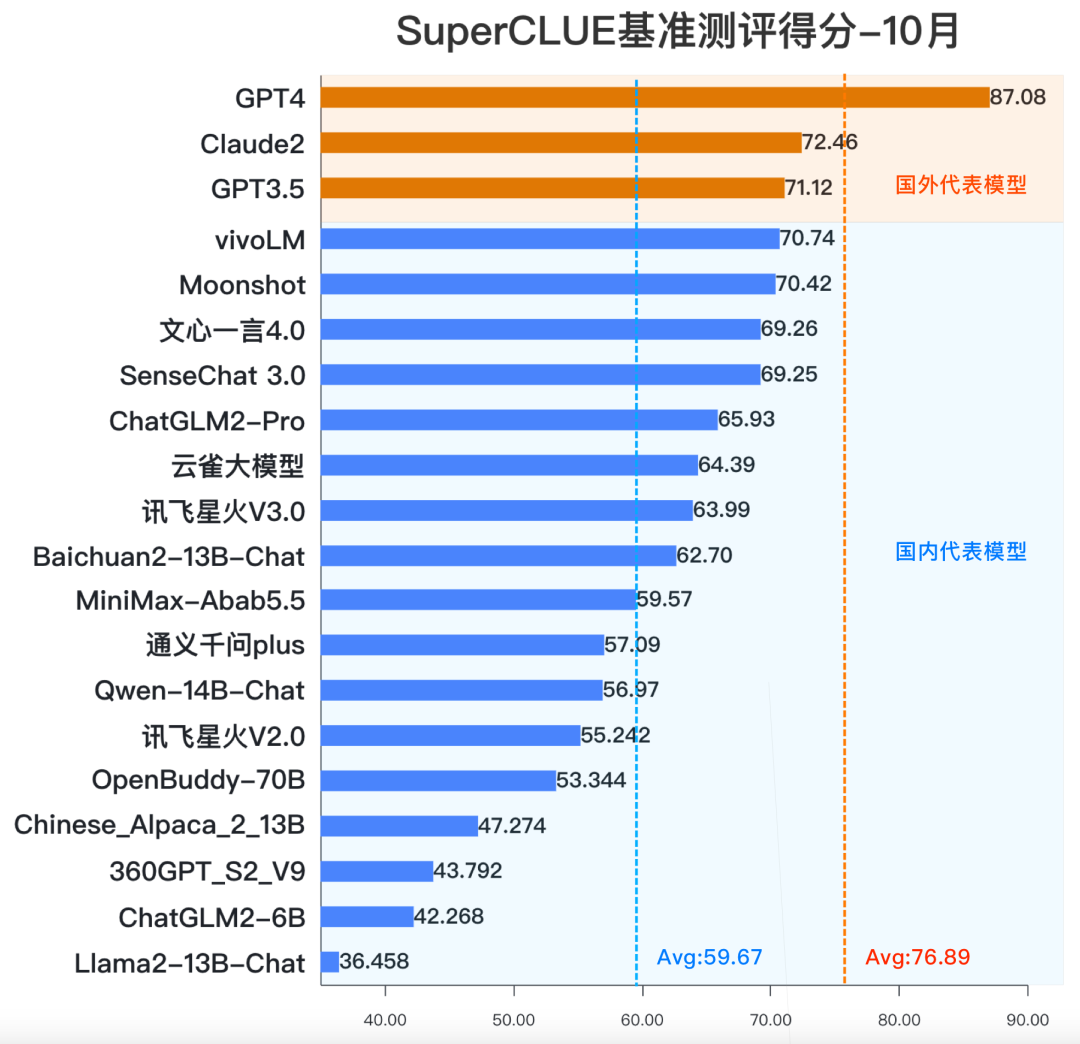
紧随vivoLM后面的分别是月之暗面的Moonshot、百度的文心一言4.0和商汤科技的SenseChat 3.0。
SuperCLUE主要考察大模型在中文能力上的表现,包括专业知识技能、语言理解与生成、AI 智能体和安全四大能力维度的上百个任务。
本次评测共选取了目前国内外最具代表性的20个通用大语言模型,与9月相比新增了月之暗面的Moonshot、百度的文心一言4.0、科大讯飞的星火V3.0、vivo的vivoLM和阿里云的Qwen-14B。

本次评测数据集为全新的3754道测试题,其中包括606道多轮简答题和3148道客观选择题,最终评选出总排行榜等5大榜单。
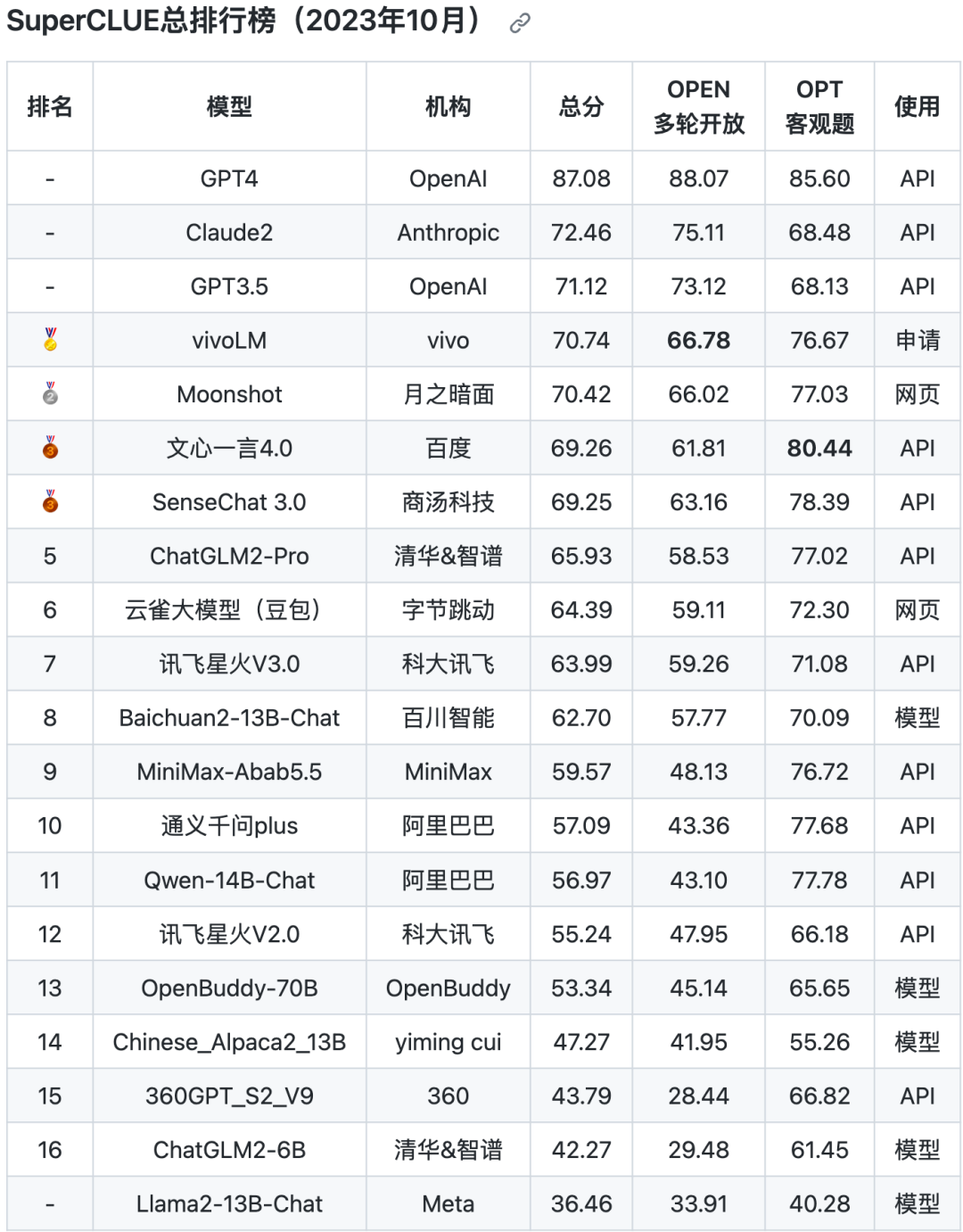
评测结果显示,国内第一梯队大模型格局已基本形成,头部的几个中文大模型已经与GPT3.5极为接近,但与GPT4的距离依然遥远,尚未发现有对标和媲美GPT4的迹象。
SuperCLUE还认为在今年第四季度内将会出现全面超越GPT3.5的通用大模型,但如何赶超GPT4,又会成为摆在所有中文模型研发机构面前的新难题。
自 快科技
更多阅读:
