
导读:关于Alfa Go的评论文章很多,但真正能够与开发团队交流的却不多,感谢Alfa Go开发团队DeepMind的朋友对我这篇文章内容的关注与探讨,指出我在之前那一版文章中用字上的不够精确,所以在此又作调整。我之前文章提到的「全局」指的是跨时间点的整场赛局,很容易被误认为是某个特定时点整个棋盘的棋局,所以后面全部都修改为「整体棋局」。此外,关于整体棋局评估,除了透过脱机数据学习的评价网络之外,还可以透过根据目前状态实时计算的不同策略评价差异(这项技术称之为Rollouts),它透过将计算结果进行快取,也能做到局部考虑整体棋局的效果。再次感谢DeepMind朋友的斧正。
在人类连输AlphaGo三局后的今天,正好是一个好时机,可以让大家对于AlphaGo所涉及的深度学习技术能够有更多的理解(而不是想象复仇者联盟中奥创将到来的恐慌)。在说明Alpha Go的深度学习技术之前,我先用几个简单的事实总结来厘清大家最常误解的问题:
●AlphaGo这次使用的技术本质上与深蓝截然不同,不再是使用暴力解题法来赢过人类。
●没错,AlphaGo是透过深度学习能够掌握更抽象的概念,但是计算机还是没有自我意识与思考。
●AlphaGo并没有理解围棋的美学与策略,他只不过是找出了2个美丽且强大的函数来决定他的落子。
什么是类神经网络?
其实类神经网络是很古老的技术了,在1943年,Warren McCulloch以及Walter Pitts首次提出神经元的数学模型,之后到了1958年,心理学家Rosenblatt提出了感知器(Perceptron)的概念,在前者神经元的结构中加入了训练修正参数的机制(也是我们俗称的学习),这时类神经网络的基本学理架构算是完成。类神经网络的神经元其实是从前端收集到各种讯号(类似神经的树突),然后将各个讯号根据权重加权后加总,然后透过活化函数转换成新讯号传送出去(类似神经元的轴突)。
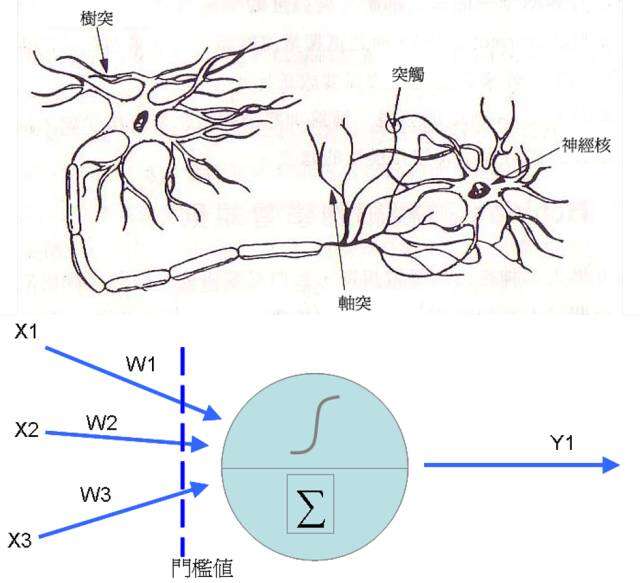
至于类神经网络则是将神经元串接起来,我们可以区分为输入层(表示输入变量),输出层(表示要预测的变量),而中间的隐藏层是用来增加神经元的复杂度,以便让它能够仿真更复杂的函数转换结构。每个神经元之间都有连结,其中都各自拥有权重,来处理讯号的加权。
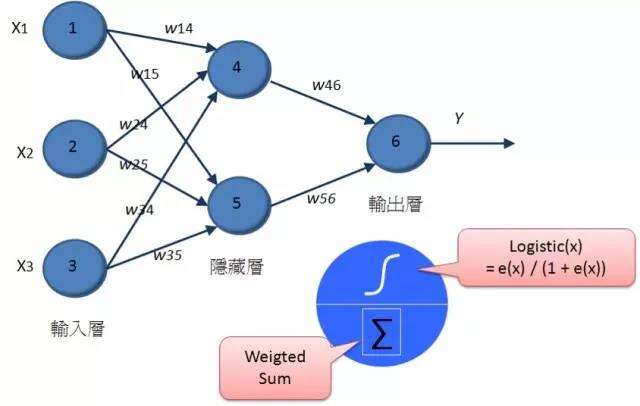
传统的类神经网络技术,就是透过随机指派权重,然后透过递归计算的方式,根据输入的训练数据,逐一修正权重,来让整体的错误率可以降到最低。随着倒传导网络、无监督式学习等技术的发展,那时一度类神经网络蔚为显学,不过人类很快就遇到了困难,那就是计算能力的不足。因为当隐藏层只有一层的时候,其实大多数的状况,类神经网络的分类预测效果其实并不会比传统统计的罗吉斯回归差太多,但是却要耗费更庞大的计算能力,但是随着隐藏层神经元的增加,或者是隐藏层的增加,那么所需要计算权重数量就会严重暴增。所以到了八十年代后期,整个类神经网络的研究就进入了寒冬,各位可能只能在洗衣机里体会到它小小威力(现在洗衣机里根据倒入衣物评估水量与运行时间很多都是用类神经网络作的),说真的,类神经网络一点都没有被认为强大。
这个寒冬一直持续到2006年,在Hinton以及Lecun小组提出了「A fast learning algorithm for deep belief nets」论文之后,终于有了复苏的希望,它们提出的观点是如果类神经网络神经元权重不是以随机方式指派,那么应该可以大幅缩短神经网络的计算时间,它们提出的方法是利用神经网络的非监督式学习来做为神经网络初始权重的指派,那时由于各家的论文期刊只要看到类神经网络字眼基本上就视为垃圾不刊登,所以他们才提出深度学习这个新的字眼突围。除了Hinton的努力之外,得力于摩尔定律的效应,我们可以用有更快的计算能力,Hinton后来在2010年使用了这套方法搭配GPU的计算,让语音识别的计算速度提升了70倍以上。深度学习的新一波高潮来自于2012年,那年的ImageNet大赛(有120万张照片作为训练组,5万张当测试组,要进行1000个类别分组)深度学习首次参赛,把过去好几年只有微幅变动的错误率,一下由26%降低到15%。而同年微软团队发布的论文中显示,他们透过深度学习将ImageNet 2012数据集的错误率降到了4.94%,比人类的错误率5.1%还低。而去年(2015年)微软再度拿下ImageNet 2015冠军,此时错误率已经降到了3.57%的超低水平,而微软用的是152层深度学习网络(我当初看到这个数字,吓都吓死了)….
卷积神经网络(Convolutional Neural Network)
在图像识别的问题上,我们处理的是一个二维的神经网络结构,以100*100像素的图片来说,其实输入数据就是这10000像素的向量(这还是指灰阶图片,如果是彩色则是30000),那如果隐藏层的神经元与输入层相当,我们等于要计算10的8次方的权重,这个数量想到就头疼,即使是透过并行计算或者是分布式计算都恐怕很难达成。因此卷积神经网络提出了两个很重要的观点:
1.局部感知域:从人类的角度来看,当我们视觉聚焦在图片的某个角落时,距离较远的像素应该是不会影响到我们视觉的,因此局部感知域的概念就是,像素指需要与邻近的像素产生连结,如此一来,我们要计算的神经连结数量就能够大幅降低。举例来说,一个神经元指需要与邻近的10*10的像素发生连结,那么我们的计算就可以从10的8次方降低至100*100*(10*10)=10的6次方了。
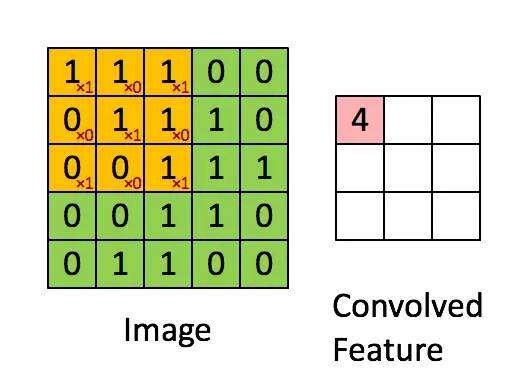
2.权重共享:但是10的6次方还是很多,所以这时要引入第二个观念就是权重共享。因为人类的视觉并不会去认像素在图片上的绝对位置,当图片发生了平移或者是位置的变化,我们都还是可以理解这个图片,这表示我从一个局部所训练出来的权重(例如10*10的卷积核)应该是可以适用于照片的各个位置的。也就是说在这个10*10范围所学习到的特征可以变成一个筛选器,套用到整个图片的范围。而权重共享造成这10*10的卷积核内就共享了相同的权重。一个卷积核可以理解为一个特征,所以神经网络中可以设计多个卷积核来提取更多的特征。下图是一个3*3的卷积核在5*5的照片中提取特征的示意图。
卷积层找出了特征后,就可以做为输入变量到一般的类神经网络进行分类模型的训练。不过当网络结构越来越复杂,样本数如果不是极为庞大,很容易会发生过度学习的问题(over-fitting,神经网络记忆的建模数据的结构,而非找到规则)。因此我们后来引入池化 (pooling)或是局部取样(subsampling)的概念,就是在卷积核中再透过n*n的小区域进行汇总,来凸显这个区域的最显著特征,以避免过度学习的问题。
所以常见的图像识别技术(例如ImageNet)就是透过多阶段的卷积层+池化层的组合,最后在接入一般的类神经网络架构来进行分类预测。下图是一个图像识别的范例。其中的C2、C4、C6都是卷积层,而S3与S5则是池化层。卷积神经网络建构了一个透过二维矩阵来解决抽象问题的神经网络技术。而图像识别不再需要像过去一样透过人工先找出图像特征给神经网络学习,而是透过卷积网络结构,它们可以自己从数据中找出特征,而且卷积层越多,能够辨识的特征就越高阶越抽象。所以你要训练神经网络从照片中辨识猫或狗,你不再需要自己找出猫或狗的特征注记,而是只要把大量的猫或狗的照片交给神经网络,它自己会找出猫或狗的抽象定义。
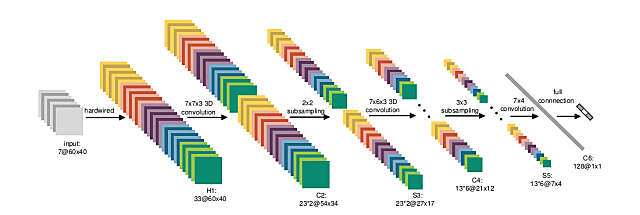
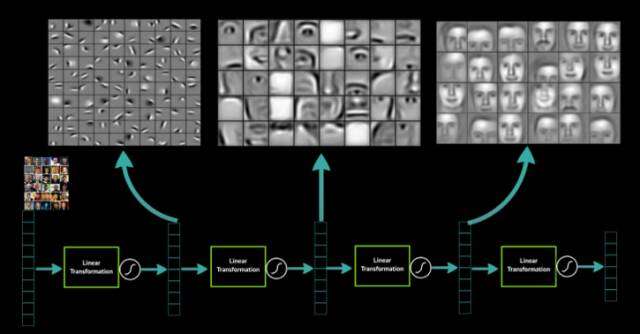
讲到这里有没有发现卷积神经网络作图像识别与围棋有甚么相似性?没错,围棋是一个19*19的方阵,而围棋也是一个规则不像象棋或西洋棋般的明确,而且具备了很高的需要透过直觉才能判断落子的特性。这个时候,深度学习就能发挥极佳的作用,因为程序设计师不需要自己把围棋的游戏规则输入给计算机,它可以透过大量的棋谱自己找出对应的逻辑与抽象概念。
为什么围棋比较困难?
为什么深蓝可以在西洋棋赢过人类但是却无法赢围棋,这是因为深蓝透过强大的计算能力,将未来局势的树状架构,推导出后面胜负的可能性。但是各位要知道,以西洋棋或中国象棋来说,它的分支因子大概是40左右,这表示预测之后20步的动作需要计算40的20次方(这是多大,就算是1GHz的处理器,也要计算3486528500050735年,请注意,这还是比较简单的西洋棋),所以他利用了像是MinMax搜索算法以及Alpha-Beta修剪法来缩减可能的计算范围,基本上是根据上层的胜率,可能胜的部分多算几层、输的少算,无关胜负不算,利用暴力解题法来找出最佳策略。但是很不幸的是,围棋的分支因子是250,以围棋19*19的方阵,共有361个落子点,所以整个围棋棋局的总排列组合数高达10的171次方,有不少报导说这比全宇宙的原子数还多,这是采用了之前的一个古老的研究说全宇宙原子数是10的75次方,不过我对此只是笑笑,我觉得这也是低估了宇宙之大吧。
AlphaGo的主要机制
在架构上,AlphaGo可以说是拥有两个大脑,两个神经网络结构几乎相同的两个独立网络:策略网络与评价网络,这两个网络基本上是个13层的卷积神经网络所构成,卷积核大小为5*5,所以基本上与存取固定长宽像素的图像识别神经网络一样,只不过我们将矩阵的输入值换成了棋盘上各个坐标点的落子状况。
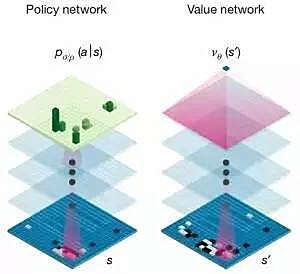
第一个大脑「策略网络」基本上就是一个单纯的监督式学习,用来判断对手最可能的落子位置。他的做法是大量的输入这个世界上职业棋手的棋谱,用来预测对手最有可能的落子位置。在这个网络中,完全不用去思考「赢」这件事,只需要能够预测对手的落子即可。目前AlphaGo预测对手落子位置的正确率是57%(这是刊登在Nature文章时的数据,现在想必更高了)。那各位可能认为AlphaGo的弱点是否应该就在策略网络,一方面是预测准确率不高,再者是如果下了之前他没看过的棋局是不是就有机会可以赢过他。可惜并不是,因为AlphaGo的策略网络有做了两个层面增强,第一个层面是利用了名为增强策略网络(reinforced-learning (RL) policy network)的技术,他先使用部分样本训练出一个基础版本的策略网络,以及使用完整样本建立出来的进阶版策略网络,然后让两个网络对弈,后者进阶版策略网络等于是站在基础版前的「高手」,因此可以让基础网络可以快速的熟即到高手可能落子的位置数据,进而又产生一个增强版,这个增强版又变成原有进阶版的「高手」,以此循环修正,就可以不断的提升对于对手(高手)落子的预测。第二个层面则是现在的策略网络不再需要在19*19的方格中找出最可能落子位置,改良过的策略网络可以先透过卷积核排除掉一些区域不去进行计算,然后再根据剩余区域找出最可能位置,虽然这可能降低AlphaGo策略网络的威力,但是这种机制却能让AlphaGo计算速度提升1000倍以上。也正因为Alpha Go一直是根据整体局势来猜测对手的可能落子选择,也因此人类耍的小心机像是刻意下几步希望扰乱计算机的落子位置,其实都是没有意义的。

第二个大脑是评价网络。在评价网络中则是关注在目前局势的状况下,每个落子位置的「最后」胜率(这也是我所谓的整体棋局),而非是短期的攻城略地。也就是说策略网络是分类问题(对方会下在哪),评价网络是评估问题(我下在这的胜率是多少)。评价网络并不是一个精确解的评价机制,因为如果要算出精确解可能会耗费极大量的计算能力,因此它只是一个近似解的网络,而且透过卷积神经网络的方式来计算出卷积核范围的平均胜率(这个做法的目的主要是要将评价函数平滑化,同时避免过度学习的问题),最终答案他会留到最后的蒙利卡罗搜索树中解决。当然,这里提到的胜率会跟向下预测的步数会有关,向下预测的步数越多,计算就越庞大,AlphaGo目前有能力自己判断需要展开的预测步数。但是如何能确保过去的样本能够正确反映胜率,而且不受到对弈双方实力的事前判断(可能下在某处会赢不是因为下在这该赢,而是这个人比较厉害),因此。这个部分它们是透过两台AlphaGo对弈的方式来解决,因为两台AlphaGo的实力可以当作是相同的,那么最后的输赢一定跟原来的两人实力无关,而是跟下的位置有关。也因此评价网络并不是透过这世界上已知的棋谱作为训练,因为人类对奕会受到双方实力的影响,透过两台对一的方式,他在与欧洲棋王对弈时,所使用的训练组样本只有3000万个棋谱,但是在与李世石比赛时却已经增加到1亿。由于人类对奕动则数小时,但是AlphaGo间对奕可能就一秒完成数局,这种方式可以快速地累积出正确的评价样本。所以先前提到机器下围棋最大困难点评价机制的部分就是这样透过卷积神经网络来解决掉。

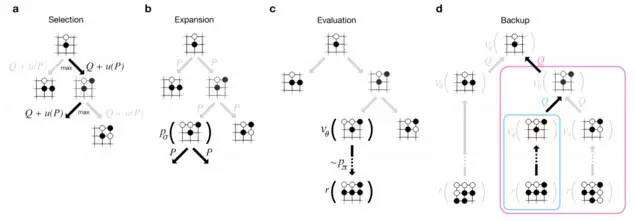
AlphaGo技术的最后环节就是蒙地卡罗搜索树,相较于以前深蓝所使用的搜索(搭配MinMax搜索算法以及Alpha-Beta修剪法,这里就不再赘述),由于我们并非具有无限大的计算能力(请注意,如果是有限的排列组合,蒙地卡罗搜索树的确有可能针对所有组合进行通盘评估,但是在围棋的场景下是没有办法的,就算这样做,恐怕也会造成计算时间的大幅增加),因此不可能是适用于旧的方法,不过在前面策略网络以及评价网络中,AlphaGo已经可以针对接下来的落子(包括对方)可能性缩小到一个可控的范围,接下来他就可以快速地运用蒙地卡罗搜索树来有限的组合中计算最佳解。一般来说蒙地卡罗搜索树包括4个步骤:
1.选取:首先根据目前的状态,选择几种可能的对手落子模式。
2.展开:根据对手的落子,展开至我们胜率最大的落子模式(我们称之为一阶蒙地卡罗树)。所以在AlphaGo的搜索树中并不会真的展开所有组合。
3.评估:如何评估最佳行动(AlphaGo该下在哪?),一种方式是将行动后的棋局丢到评价网络来评估胜率,第二种方式则是做更深度的蒙地卡罗树(多预测几阶可能的结果)。这两种方法所评估的结果可能截然不同,AlphaGo使用了混合系数(mixing coefficient)来将两种评估结果整合,目前在Nature刊出的混合系数是50%-50%(但是我猜实际一定不是)
4.倒传导:在决定我们最佳行动位置后,很快地根据这个位置向下透过策略网络评估对手可能的下一步,以及对应的搜索评估。所以AlphaGo其实最恐怖的是,李世石在思考自己该下哪里的时候,不但AlphaGo可能早就猜出了他可能下的位置,而且正利用他在思考的时间继续向下计算后面的棋路。
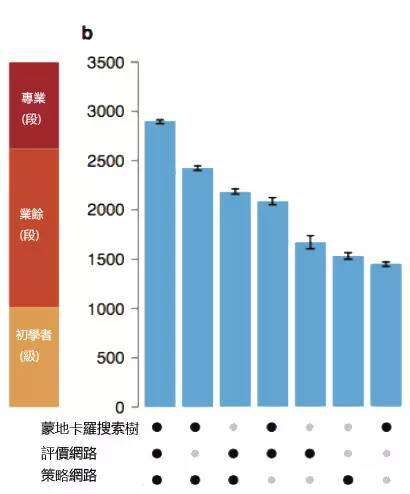
根据AlphaGo团队的实测,如果单独使用一个大脑或是蒙利卡罗搜索树技术,都能达到业余(段)的等级(欧洲棋王樊摩强度等级大概是在2500~2600,而李世石是在3500以上)。但是当这些技术整合就能呈现更强大的力量。但是在刊登Nature论文时他的预估强度大概也只有职业3~4段(李世石是9段),不过刚刚提到他透过增强技术强化策略网络、透过两台AlphaGo来优化评价网络,这都可以让他可以在短时间变得更加强大。而且计算机没有情感也不怕压力,更不会因为对手表现而轻敌(AlphaGo的策略网络一向只预测强者),所以人类就算有更强大的实力也未必能够承受输赢压力而做最好的发挥。
李世石有没有赢的机会?
在很多评论中,我觉得对于AlphaGo都有很多不正确的猜测,首先是AlphaGo有没有「整体棋局」评估的能力,必须说的是以整台AlphaGo来说是有的,这主要是来自于评价网络的计算结果(因为它计算的是最后胜率),但是获得的是个池化区域的平滑化后平均胜率。在AlphaGo的策略网络主要是针对对手接下来的落子进行评估,至于蒙地卡罗搜索树则是使用了评价网络的参数(脱机训练的结果)以及根据目前状态实时计算价值差异的Rollouts技术,所以可以做出具有整体棋局考虑的模拟试算。但是人类对于「整体棋局」的掌控是透过直觉,这一点应该还是比计算机强大,而且如果利用目前AlphaGo是透过卷积核池化过后结果评估平均胜率(主要是为了平滑化以及避免过度学习),如果李世石有办法利用AlphaGo会预测他的行为做后面决策,作出陷阱,来制造胜率评估的误区(在池化范围内平均是高胜率,但是某个位子下错就造成「整体棋局」翻覆的状况,这就是胜率预测的误区),那么人类就有可能获胜(当然啦,我这里只是提出可能性,但是知易行难,这样的行动的实际执行可能性是偏低的)。现在李世石必输的原因在于它一直在猜测AlphaGo的棋路,但是事实上反而是AlphaGo一直在靠猜测李世石的下一步来做决策,所以他应该改变思路,透过自己的假动作来诱骗AlphaGo,这才有可能有胜利的可能性。
弱人工智能与强人工智能
现在计算机在围棋这个号称人类最后的堡垒中胜过了人类,那我们是不是要担心人工智能统治人类的一天到来,其实不必杞人忧天,因为在人工智能的分类上来说,区分为弱人工智能(Artificial Narrow Intelligence)与强人工智能(Artificial General Intelligence)(事实上还有人提出高人工智能Artificial Super Intelligence,认为是比人类智力更强大,具备创造创新与社交技能的人工智能,但我觉得这太科幻了,不再讨论范围内),其中最大的差别在于弱人工智能不具备自我意识、不具备理解问题、也不具备思考、计划解决问题的能力。各位可能要质疑AlphaGo如果不能理解围棋他是如何可以下的那么好?请注意,AlphaGo本质上就是一个深度学习的神经网络,他只是透过网络架构与大量样本找到了可以预测对手落子(策略网络)、计算胜率(评价网络)以及根据有限选项中计算最佳解的蒙地卡罗搜索树,也就是说,他是根据这三个函数来找出最佳动作,而不是真的理解了什么是围棋。所以AlphaGo在本质上与微软的Cortana或iPhone的Siri其实差别只是专精在下围棋罢了,并没有多出什么思考机制。我也看到一些报导乱说AlphaGo是个通用性的网络,所以之后叫他学打魔兽或是学医都能够快速上手,那这也是很大的谬误,如果各位看完了上面的说明,就会知道AlphaGo根本就是为了下围棋所设计出来的人工智能,如果要拿它来解决其他问题,势必神经结构以及算法都必须要重新设计。所以李世石与其说是输给了AlphaGo,还不如说是输给了数学,证明其实直觉还是不如数学的理性判断。有人觉得人类输掉了最后的堡垒,围棋这项艺术也要毁灭了…其实各位真的不用太担心。人类跑不过汽车的时候为何没有那么恐慌呢?跑步这项运动到现在也好好的,奥运金牌也不是都被法拉利拿走了…所以真的不必太过紧张。
那么会有强人工智能出现的一天吗?在2013年Bostrom对全球数百位最前沿的人工智能专家做了问卷,问了到底他们预期强人工智能什么时候会出现,他根据问卷结果推导出了三个答案:乐观估计(有10%的问卷中位数)是2022年,正常估计(50%的问卷中位数)是2040年,悲观估计(90%的问卷中位数)是2075年。所以离我们还久的呢。不过当弱人工智能的发展进入到成本降低可商业化的时候,大家与其关心人工智能会不会统治地球,还不如先关心自己的工作技能会不会被计算机取代来实际些吧。
来源:华院数据
更多阅读:
