
很多人都知道谷歌在去年推出了一个叫做 RankBrain 的机器学习人工智能系统来对搜索结果进行排序,这可能是山景城(谷歌总部所在地)最新的一项伟大发明。但不是所有人都知道这个系统对整个 SEO(搜索引擎优化)产业的影响有多大。在这篇文章中,我将会带你详细了解以前的 SEO 规则如何失效,而为了你的生意你应该如何进行顺应潮流的 SEO。
在我们预测未来之前,让我们先回顾一下 RankBrain是如何改变 SEO 的。我现在跟 Market Brew 的 CTO Scott Stouffer 坐在一起,Market Brew 是一家专为财富 500 强公司提供搜索引擎优化的公司。作为一名搜索引擎工程师,Stouffer 对 SEO 产业过去十年的发展有着很多独特观察。以下是他对加入了人工智能后的 SEO 工作的几点建议。
一、当前的回归分析有着严重的错误
回归分析(regression analysis)是当前 SEO 产业最大的谬误。每一次谷歌的排名算法调整时都会出现一大批预言家,通常我们这个行业里的一些数据科学家和知名公司的 CTO 们会宣称他们对谷歌的收录刷新(Google Dance:Google搜索引擎数据库每月一次的大规模升级)有自己的应对之道。典型的分析包括审阅过去几个月的排名数据事件,然后观察新的排名规则正在偏向于哪些类型的网站。
通过当前的这种回归分析,这些数据科学家们会指出某种类型的网站已经被影响了(排名上升或者排名下降),然后十分确信地得出一个结论:谷歌的最新排名算法就是为这种类型的网站设计的。
然而,这已经不再是谷歌的工作模式了。谷歌的机器学习和深度学习算法 RankBrain 正在以一种非常不同的方式工作。
谷歌内部存在着许多核心算法,而 RankBrain 的工作就是学习这些核心算法并将其应用到不同类型的搜索结果排名中。举个例子,RankBrain 可能已经知道一个网页最重要的标志是它的标题标记(META Title)。
在标题标记上多增加关注可能会带来更好的搜索体验,但是在不同的搜索结果中,相同的标题可能会带来完全不同的搜索体验。因为在不同的垂直领域中,其他的算法——例如 PageRank——可能被提升了。
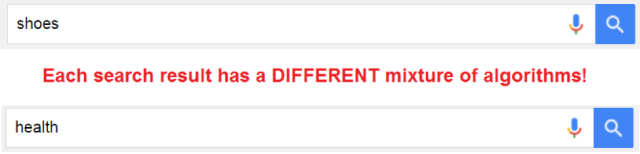
这就意味着,在每一个搜索结果中,谷歌都使用了不同的混合算法。现在你就可以明白为什么仅仅对每个页面进行回归分析,而不是分析搜索结果的文本,是一个超级谬误了。
在这个意义上,现在的回归分析应该分析每一个具体的搜索结果,而不是网页本身。Stouffer 最近写了一篇文章认为通过一种搜索模型的方法能够帮助我们解决谷歌算法调整的问题。首先,你可以简要得了解一下搜索引擎模型在过去的一段时间为某个特定的关键词做出了何种调整。然后,在确定新的已经被调整过的搜索引擎模型并将其测定出来,然后为两种搜索引擎模型设定做一个三角分析。通过这种方法以及确定的模型调整分析,你就可以看到某种特定的算法在调整中是被加权了还是降权了。
有了这些知识,我们可以为不同的搜索结果定制和升级特定的 SEO 策略。但是相同的方法无法适用于所有的搜索结果。这就是 RankBrain 是在搜索结果(或关键词)的层面上操作的原因。它其实是在为不同的搜索结果定制算法。
二、专注自己的垂直领域以避免被错误地分类
谷歌最近还意识到他们可以让 RankBrain 这个深度学习系统知道好网站和坏网站长什么样。跟如何为不同的搜索结果定制算法一样,他们还意识到不同垂直领域有着不同的好网站和坏网站的样本。这无疑是因为不同领域有着不同的 CRM(客户管理系统),也就是根据数据结合得出的不同的模型和不同的结构。
当 RankBrain 运行时,他们必须学习每种环境对应哪种正确的设置。你可能已经猜到了,这些设置完全取决于对应的垂直领域。因此,例如在健康产业,谷歌知道像 WebMD.com 这样的网站的声誉比较好,所以这个网站的搜索结果就会比较靠前。而与 WebMD 的网站结构相似的其它网站就会被与「好网站」联系起来。类似的,任何与知名垃圾医疗网站的结构相似的网站都会与「坏网站」联系起来。
当 RankBrain 把「好网站」和「坏网站」联系起来工作时,用的是它的深度学习能力,但如果你的网站结合了很多不同领域的内容呢?
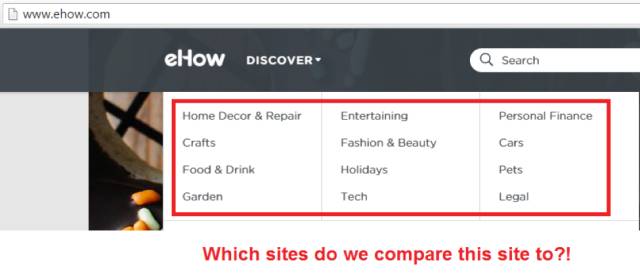
首先,我们得更详细地讨论这种深度学习是如何工作的。在将一个网站归类到「好网站」和「坏网站」之前,RankBrain 必须首先确定每个网站的分类结构。对于 Nike.com 和 WebMD.com 这样的网站来说当然是很简单的。每个网站都会有不同的分类目录,而其总目录则是非常简单直接的。所以这种网站会很容易分类。
但是对于有着不同的分类目录的网站来说,例如 How-To(类似于百度经验,提供针对各种事情的解决方法)类的百科网站,它们有相当多的信息分类目录。在这些案例里,深度学习进程就会失效。那么谷歌是在用哪些数据进行排序的呢?答案是:随机。例如对于维基百科这样的网站,谷歌会将其排出在 RankBrain 的控制之外,以确保这个深度学习系统不会破坏当前的搜索体验。
而对于那些不如维基百科这般知名的网站会怎么样呢?答案是:谁知道呢?大概这个机器学习系统能在将它们进行对比之前对它们进行分类吧。我们还是说一说像 WebMD 这样的网站吧。
如果分类程序认为这个网站是关于鞋子的,那么它就会将其与 Nike 的网站结构做一下对比,而不是 WebMD 的。如果一个卖鞋的网站有着和 WebMD 的网站一样的结构,而不是像 Nike 这样的,那么它就很有可能被判为垃圾网站。而对于 How-To 类网站来说,最好是将不同的垂直领域划分到不同的子域名下,以方便 RankBrain 进行分类。
三、反向链接
让我们来看看 RankBrain 如何影响反向链接(backlinks)。基于以上的分类程序来判断,你的网站上的友情链接也会让 RankBrain 知道你是否属于这个垂直领域。
还是举以上的例子,如果一家公司拥有一个关于鞋子的网站。我们知道 RankBrain 的深度学习系统将会尝试将这个网站的每一个方面与鞋子产业的最好和最坏的网站进行对比。因此,很自然地,这个网站的反向链接也会被拿来与那些最好的和最坏的网站的反向链接进行对比。
我们假设一个声誉良好的鞋子网站有来自以下网站的反向链接:
- 体育
- 健康
- 时尚
现在假设这家公司的 SEO 团队决定增加来自这些网站的反向链接。而因为这家公司的老板此前在汽车行业工作,因此他有很多汽车行业的资源。所以 SEO 团队决定再加上一些来自汽车产业的反向链接。他们在一个汽车行业网站上打了一个互推广告,指向他们的网站的链接是一个关于“新鞋租赁服务”的页面。看起来很和谐,对吗?
但是,RankBrain 会认为这种反向链接与其他声誉良好的鞋子网站看起来不一样。更糟糕的是,它还发现很多关于鞋子的垃圾网站也有一堆来自汽车行业的反向链接。所以,在不知道什么是正确的反向链接的情况下,RankBrain 已经从搜索结果中嗅到了什么是「好网站」和什么是「坏网站」的迹象了。所以这个新网站被打上了「坏网站」的标签,网站流量急速下降。
四、人工智能和 SEO 的未来
加速回报定律(Law of Accelerating Returns)告诉我们,像 RankBrain 这样的人工智能将很快在某些领域超越人脑。从这个角度上看,没有人知道这项技术会将我们带向何方。
然而这些东西是确定的:
- 每一个竞争激烈的关键词领域都需要自我检讨
- 每个网站都需要专注自己的垂直领域以避免被错误地分类
- 每个网站都需要向自己所在领域的顶级网站学习结构和内容
在某些情况下,这种深度学习算法让 SEO 变得相对简单了。因为我们已经知道 RankBrain 和类似的技术已经和人脑不相上下了,所以规则就会很明确:没有任何空子可钻。
另一方面,情况又更加复杂了,SEO 仍将是一门技术活。分析学和大数据将会成为主流,任何 SEO 从业人员如果不熟悉这些方法的话,都会遇到很多困难。而拥有这些技能的人将会坐等加薪。
©本文由机器之心编译
更多阅读:
