

以机器学习为代表的人工智能领域目前是科技领域最热门的方向之一,它被称为新时代的水电煤,会为所有产业带来基础性的革命。但对于一家公司、一个部门、一款产品和一位产品经理来说,他们需要一个简单而重要的答案:我真的需要机器学习吗?
你真的需要机器学习吗?
很多公司和科技博客都在一直鼓吹“人工智能”代表未来,并提出他们会如何运用“机器学习”来改进科技,在竞争中脱颖而出。但是机器学习到底是什么,你应该怎么使用它?又或者它只是2017年的一个时髦热词而已?
长话短说,以上问题的答案是肯定的,在大多数情况下 – 但是在它可以提供帮助的地方,机器学习可以是革命性的。
所以机器学习到底是什么?以它最原始的形式来说,机器学习是一项实践函数逼近(function approximation)的艺术,或者说是要做出有根据的推测。它和专业人员的经验是相同的概念,比如管道工拥有根据房屋中漏水情况快速、准确地判断造成漏水原因的经验。在机器学习中,我们称这样的经验为“大数据”。在遇到和解决的每一个问题之后,管道工会得到一个新的数据点,她可以使用这些知识来解决将来会遇到的、相似的问题。
上面提到的这些看起来都很棒,但是对于近期机器学习热度的跃升,我敢于称其为时髦术语也是有原因的。机器学习几乎从来都不是问题的终极答案。机器学习会很容易让简单的问题变的异常复杂 – 比如想要重新发明for循环的想法是完全站不住脚的。大多数所谓使用“机器学习”的公司或者是没有真的使用机器学习的技术,或者是把普通的算法开发称作机器学习来达到市场宣传的效果,又或者是在产出过度复杂、计算量巨大、价格昂贵并且根本不必要的解决方案,想要解决一些本来可以使用常规手段解决的问题。
这并不意味着机器学习永远都没有用处。事实上,当把它正确地运用在适合的问题上,机器学习可以是一件不可思议的工具。但什么是一个适合的问题哪?虽然不是一个机器学习问题盖棺定论的定义,这里有一个简便的清单,来确定一个问题是否值得使用机器学习的方式,还是说更适合用标准的解析办法。
作为一个机器学习问题:
- 会有“大数据” – 许多许多数据点(一个大型的项目如果没有上百万个数据点的话,也许不会见到很好的效果)
- 是一个复杂的问题 – 一般是一个以标准模式非常难以解决的问题,经常会需要一个领域中的专家
- 是具备不确定性的 – 一样的输入不一定产生一样的输出
- 是有多维度的 – 经验法则是数据点的采集是从最少9各方面来做的时候,这样的问题会更适合机器学习方式
一些符合这个清单的、流行的机器学习问题的例子包括:医疗图片处理,产品推荐,语音理解,文字分析,面部识别,搜索引擎,自动驾驶车辆,扩增现实,预测人类行为。
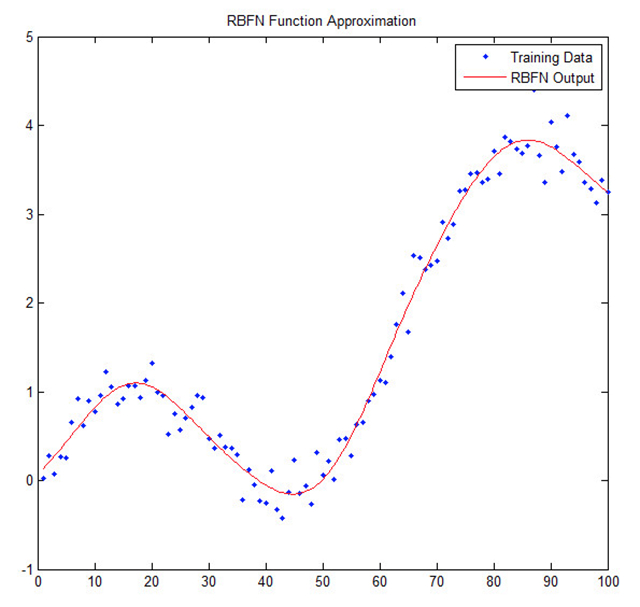
机器学习面临的其中一项最大的挑战是如何处理系统中的不确定性,不确定性是指同样的输入不一定会产生一样的输出结果。针对这个问题,我们会在这篇文章中以例子的形式来解释,这个例子是预测多伦多的天气。在这个例子中,我们有大数据 – 包括上百年的多伦多的天气资料。 这个问题足够复杂,准确的天气预测需要具备气象科学训练和经验的专家。这个问题是具备不确定性的,2016年2月23日天气冷并不意味着2017年2月23日天气也会是一样的,尽管他们分享一样的历史数据。这个问题同时也是多维度的 – 风向模式,雨量模式和任何一个会影响天气的因素都可以成为解决问题的一个新的维度。因为这个问题是具备不确定性的,我们必须使用我们有的信息,尽量好的去预测系统的输出结果(预测天气)- 我们要做出最合理的猜测。
对于机器学习来讲,我们的最合理猜测或者函数逼近几乎总是关于对于数学的创造性运用 – 这可能包括统计学/概率论,向量学,优化或者其他数学的方法。存在着几种核心的机器学习问题,他们可以帮助我们确定什么样的解决方法可以最好的解决一个问题:分类学,回归分析和聚类。在例子中,我们见到的是一个回归分析的问题 – 从数据中预测持续性的趋势。存在着几种核心的方法去训练系统,或者说给系统提供经验去学习,这些方法包括:有监督学习,无监督学习和强化学习。在我们的例子中展示的是有监督学习,在这个例子中,所有用来训练的数据的输入和输入都是已知的。我们给出一个历史日期(输入)就可以知道当天多伦多的天气(输出)。定义问题和训练模型让决定使用什么样的方法去训练机器学习算法变的更加简单。
到了这里,你已经决定要预测天气(或者解决一个不同的机器学习问题)而且你已经使用上面的清单确定了这是一个真实有意义的问题。但是应该是从哪里入手哪?下面是一个关于解决机器学习问题步骤的简便指南:
- 定义有意义的数据
- 定义问题
- 定义解决问题的方法
- 产出训练和测试数据 – 从经验来讲,应该保持70%的训练数据量,30%的测试数据量
- 训练和测试算法
让我们用我们天气预测的问题来实践一下上面提到的步骤:
第一步是定义有意义的数据。什么样的属性是有意义的,怎么样去定义一个“好”的数据点和“坏”的数据点?我们可以拿几个我们例子中的属性来解释一下,比如让我们取温度,降雨量和风速这三个属性,把这三个属性放在一起,我们可以基本了解到特定的一天天气如何。如果同时有像特定一天多伦多人年龄中位数这样的属性,我们就应该把这样的属性排除在有效数据之外,因为这样的属性跟我们要解决的问题并没有关系,而且有可能会影响最终的结果。
第二步,我们已经确定问题是一个回归分析的问题,并且应该使用有监督学习的方法。第三步需要选择一个真正的机器学习方法,在这我们不会讨论太多细节,简单来说让我们选择线性回归。第四步是取得训练数据(留下30%的数据做测试之用)。第五步就是 实际的训练和测试。
也许你已经从上面的步骤中发现了,实际去训练算法是最后也只是最不重要的一步。创造一个强大的机器学习的重要的一步是在编程之前,就确保你拥有有意义的数据,一个定义清晰、明确的问题和解决方案。
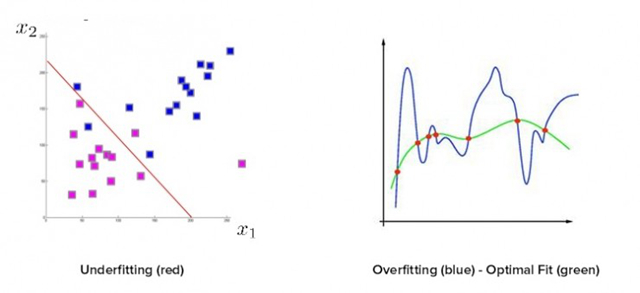
即使你有了定义清晰、分类准确的解决方案,有意义的数据,正确的测试数据,在数据趋势中包括了异常值,仍然有很多地方可能出错。在很多机器方案背后,最常见也是最致命的错误是低度拟合/过度拟合。低度拟合,或者也叫过高偏差,意味着最终的近似函数太过简单,不能很好地代表数据的趋势。想象一下我们试图画一条直线穿过多伦多一年温度的图表,这条直线很难撞到任何一个数据点。在低度拟合和过度拟合两者中,更常见也更危险的是过度拟合,或者也叫过高方差。在这个情况中,最后的近似函数会太过复杂,也不能很好地表现数据趋势。过度拟合经常产生比低度拟合更差的结果,大家也很容易落入这样的陷阱。
这篇文章只是一个关于机器学习的基本介绍,更多的学习资料正变的更加普遍,在很多语言和GUIs中(目前一些最好的机器学习的资料是用Python写就的),已经出现非常多即用型的机器学习算法和测试数据可以被用来做实验,其中包括Theano, Tensorflow, Weka甚至包括Octave和Matlab。
更多阅读:
