
介绍
“讲故事”的主意是极好的:将一个想法或事件变成一个故事。它将想法带进生活,并为其增添了乐趣。这发生在我们的日常生活中。无论我们陈述一个有趣的事件还是新发现,故事总是吸引听众和读者兴趣的首选。
例如,当我们谈论一个朋友是如何被老师责骂时,我们倾向于从头开始讲述事件,这样故事才能流畅。
对于一个 “常见的导致驾驶分心的原因” 的案例,我们以性别分类,可以有2种方式去讲述它:
第一种方式,给出如下的统计数据:
- 6%的男性认为发短信是一种干扰,而女性有4.2%这样认为;
- 儿童在车里可能导致9.8%的男性分心,而女性分心的有26.3%。
第二种方式,以下面这种视觉的方式,重新创建类似的统计信息:
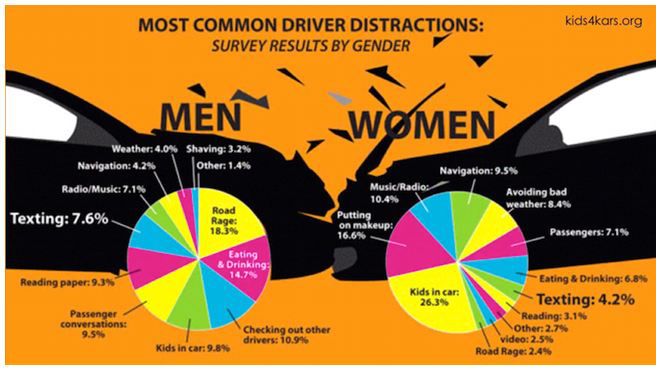
你觉得哪种,讲述了一个更好的故事?
目录
一、讲故事的必要性
二、如何创造故事?
1. 从纸—笔开始
2. 深入挖掘,找出你的故事的唯一目的
3. 使用一个强大的标题
4. 设计 “路线图”
5. 简要的总结
三、数据类型和合适的图表
1. 文本 [Wordclouds 文字云]
2. 混合 [Facet Grids 面网格]
3. 数字 [Line Charts/Bar Charts 折线图/条形图]
4. 股票 [Candlestick Charts 烛台图]
5. 地理 [Maps 地图]
四、预测模型步骤中的故事
1. 数据探索
2. 特征可视化
3. 模型创建
4. 模型比较
五、讲故事的最佳实践
六、结尾语
一、讲故事的必要性
讲故事的艺术,既简单又复杂。故事激发思考,并能提出以前没有被理解或被解释的见解。在数据驱动操作中,它经常被忽视,因为我们认为这只是一项微不足道的任务。我们没有意识到的是,再好的故事,如果没有很好地呈现出来,也终究毫无用处!
在一些公司中,分析任何事件的第一步是将故事载入其中。提问如,为什么我们要分析它?我们能从中作出什么决定?有时,单凭数据就可以讲述一些直观或复杂的故事,我们就不需要再运行复杂的相关性来证实了。
需要故事和图像来解释数据的一个最好的例子是 “Anscombe四重奏解析”。“Anscombe四重奏”中包含四个数据集,它们拥有非常相似的统计结论,但当你将它们可视化后,结果却完全不同。
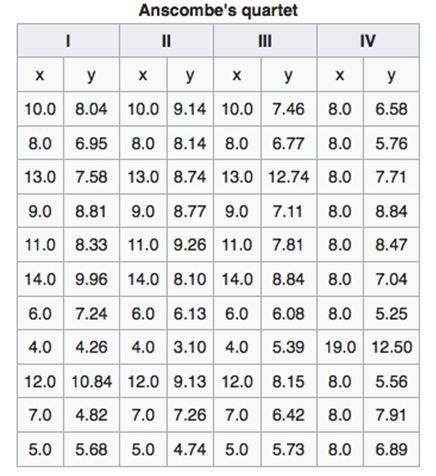
以上是 “Anscombe四重奏”中描述的4个数据集。如果只看数字,会发现它们的汇总统计数据几乎是相同的。
让我们看看可视化后,它们的样子:
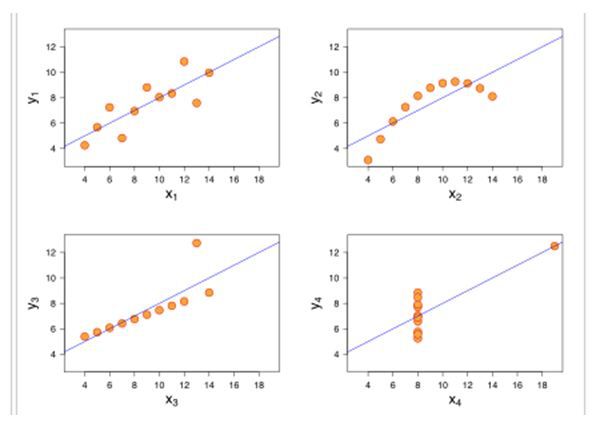
你有想过这四个数据集会呈现如此不同的视觉效果吗?
二、如何创造故事?
创造故事或一个情节是推进你的想法的第一步。大多数人没有去思考他们自己的故事,也就无法区别于平庸。让我举个例子,指导你完成创建故事的步骤。
我们将探索一个数据集,该数据集包含新闻头条和纳斯达克100家科技公司每支股票的详细价格记录 ( NASDAQ-100 technology sector)。
选择的列名如下:

1. 从纸—笔开始
视觉上引人入胜的演示文稿将启发你的听众,但它们肯定需要投入更多的工作。其中一个最好的演示文稿是在粗糙的页面和薄纸上创建的。
在你创建你的故事前写下想法和流程,对于最终的成品非常关键。
为了显著地提高你的分析,你要做的最重要的一件事是要讲一个故事。你生成的流程最终的结果中可能会有很多冲突。
亚里士多德的经典五点计划,有助于提供强烈的影响:
- 传递一个能引起听众兴趣的故事或观点;
- 提出一个必须解决或回答的问题;
- 为你提出的问题提供一种答案;
- 描述采用该答案下的行动方案的具体的好处;
- 提出行动号召。
我构建报告的一般方式是加入图表,它们能让我更好的理解数据。
我的第一个想法是,通过使用手头上的数据,如何能做出更好的股票业务决策?
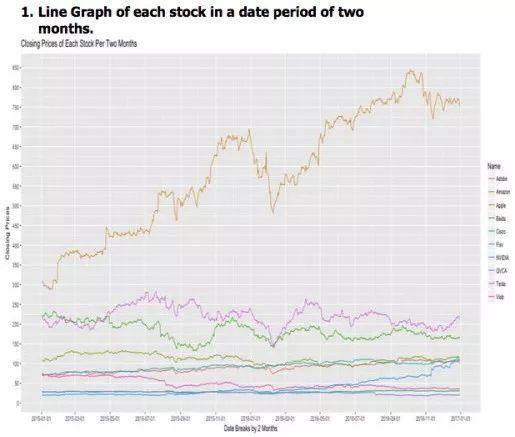
使用折线图可以帮助我分析特定股票价格的趋势线。
如我所见,2016年2月所有股票都下跌了。这将帮助我从那个事件段中搜索新闻,以确定导致下降的原因。现在,我该如何选择从哪个新闻源获取信息?

通过确定哪个新闻源对某一特定股票报告的最多,我们将有理由相信,对于该支股票,那将是一个不错的信息来源。
2. 深入挖掘,找出你的故事的唯一目的
- 仔细辨认,你的故事是什么意思。问问自己,“用这个故事我真正地给出的是什么?” 不是故事本身,而是故事能做什么,以使你做出更好的决策。你展示的是一个更好的决策或分析的想法。【果壳与果仁儿的关系】
- 提出一个“个人激情宣言”。用一句话,说出你的期望和为什么你对于使用这样的想法而由衷得感到兴奋。你的激情宣言将被铭记很久。

3. 使用强大的标题
- 创建你的标题,一句话来陈述你的故事,视觉或分析。最有效的标题是简洁的,具体的,并能提供给个人好处的。
- 记住,你的标题是一个能使你的听众更好地去理解的观点。不是关于你自己的,也不是关于他们的。
4. 设计一个路线图
- 创建一个清单,其中包含所有你想让听众,从你的故事,视觉化或分析中知道的关键词.
- 对该清单分类,直到只剩下3个主要信息点。这3个点构成一组将为你的故事提供纵向路线.
- 在每条关键信息的下面,添加支持证据以增强叙述。可以是个人故事,事实,例子,类比等。

5. 简要的总结
现在你已经提出了你故事中的所有关键点,你的结论应该简短有力。在我的报告中,我提到了3–4行的总结来说明为什么要买某支股票。

三、数据类型和合适的图表
让我们了解一下常见数据类型和如何通过选择最适合的图表来讲述故事。
常见的数据类型:
1. 文本数据
当数据以这种形式发现时,通常很容易找出一个词被使用的频率或文本情感。使用这种形式的数据可以最好地讲述故事。
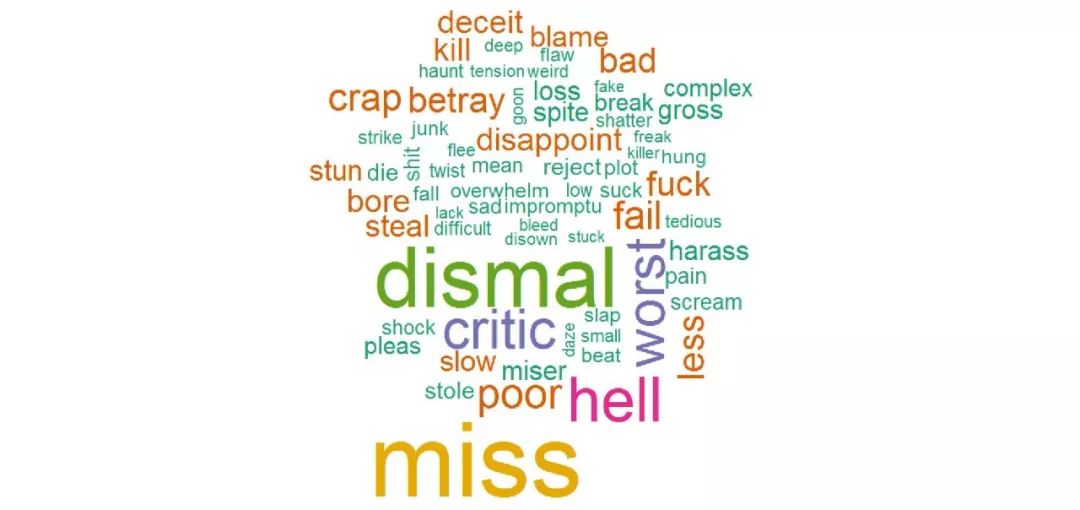
文本数据最适合的可视化方式之一是“文字云”。它的机理是,将更频繁的词放到中心并放大它们,让我们清楚地了解文本的一般概念所描绘的内容。
例如,上面显示的文字云给出了Twitter数据集的表示。这表明dismal和miss是最常用的消极词。
2. 混合数据
当我们的数据由数字或者其它各种格式组成时,我们需要知道哪些格式是重要的,并从数据集中得到好的见解。
这种数据的首选视觉效果可能会有所不同;这里我将向你展示如何使用“平面网格”来处理数据。我将使用的是泰坦尼克号的乘客数据。
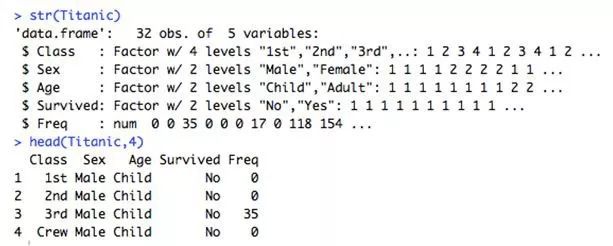
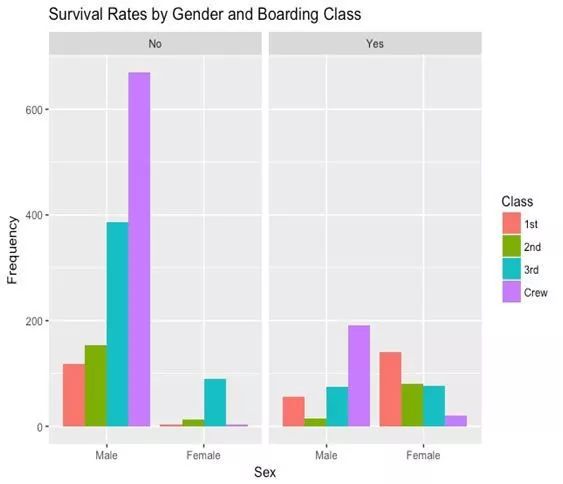
正如这张图所示,女性和头等舱乘客的生存几率高于机组成员或较低舱位的男性。
这不正是泰坦尼克号上真正发生的事吗?
另一种可视化此类数据的方式是尝试使用“多变量图”。下面是关于汽车性能和规格的数据集。
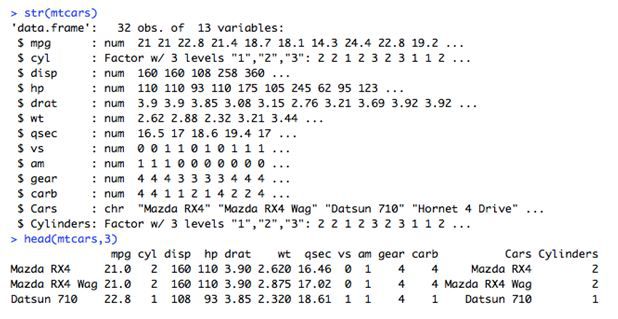
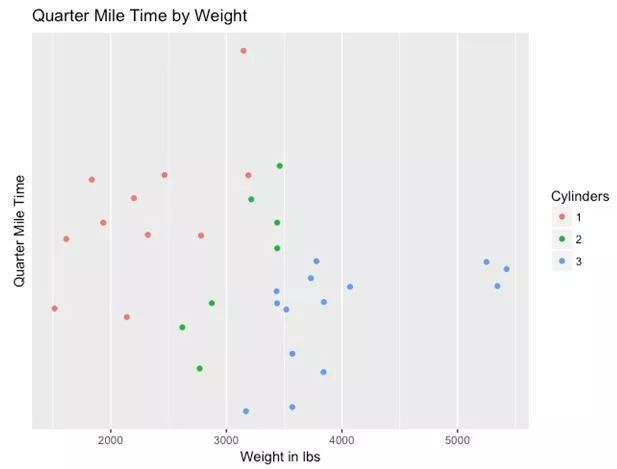
这里我们能看到,拥有更重车身的汽车比那些拥有更轻车身的汽车慢。有道理,对吗?
3. 数字数据
当我们遇到这种数据时,通常会寻找描述数字的线条或趋势。折线图会是不错的选择。
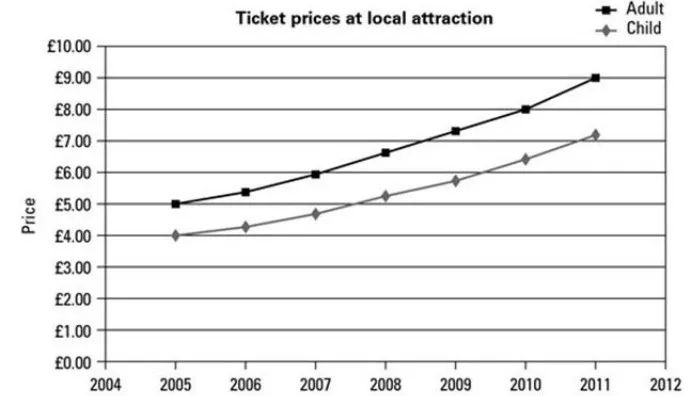
这里我们可以很清晰地看到,成人和儿童在当地景点的价格上涨。很容易就看出每年的增长幅度。
4. 股票
我们还会碰到与股票有关的数据集。股市数据主要是一个数值数据的时间序列,但作为一个交易员或投资者,我想谨慎地了解每个日期和下跌信息。
在这方面,最具吸引力的可视化方式是“烛台图”。
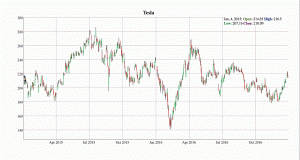
这里我们以特斯拉股票为例。烛台图可以在每个日期上操纵,并单独查看股票的高低。这有助于我们根据当前或过去的市场趋势做出更好的投资决策。
如图所示,2016年2月特斯拉股票下跌。我们可以利用这些信息来了解其它市场情况和经济状况,从而对它们的股票做出决策。
5. 地理数据
当我们有关于特定位置和区域的数据时,我们使用地图来增加分析的清晰度和意义。
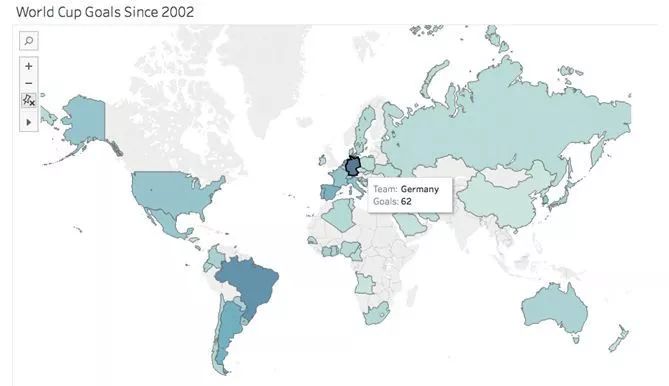
在这个例子中,我们可以看到各国在2002年世界杯前后的表现。德国队进球最多,是世界足球史上最具统治力的球队之一。
四、在预测模型的每一步中讲述故事
我们经常被问到,故事和视觉效果在创建数据模型时,是如何起作用或提供帮助的。在预测建模的所有阶段中,讲述故事可能是对分析的重要补充。
让我们了解从数据中创建模型并在其中讲述故事的基本步骤。
1. 数据探索
建模的第一步是了解你的数据。我将向你展示如何在不计算复杂的统计数据的情况下,探索数据。
这是一个关于葡萄酒质量的数据集。该数据集的结构如下:
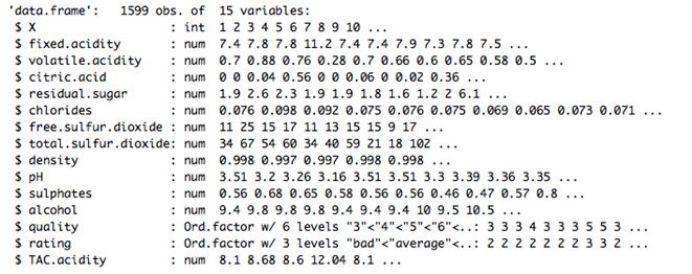
这里是对该数据集的相关统计摘要:
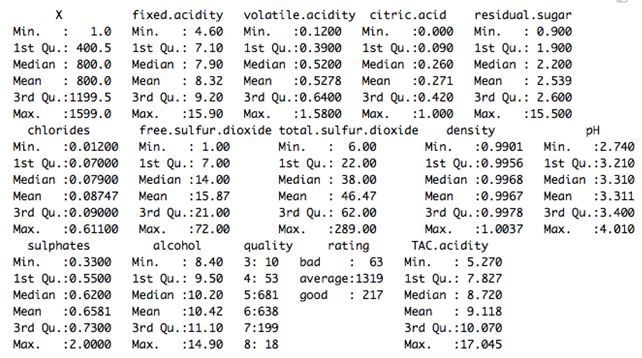
所以,如果我们需要看酒精量和葡萄酒质量间是否有任何关系时,该怎么做呢?
可以计算Pearson的‘r’。它将帮助我们建立模型,但不会帮我们分析太多。

这表明酒精含量与葡萄酒质量之间存在很强的相关性。 但它会告诉你其他什么吗?
理想情况下,它没有。 那么,有什么用呢?
让我们看看,如何从可视化中了解更多。
首先,我们看红酒质量是怎样和酒精含量相关的。
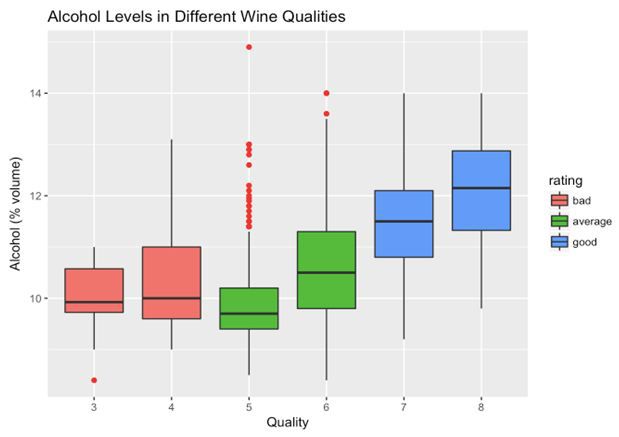
可以看出,酒精含量越高,葡萄酒质量越好,这有助于我们更好地了解我们的数据。在这种情况下,我们还能发现异常值。
接下来,你会想知道葡萄酒中的酸含量是如何影响其质量的吗?
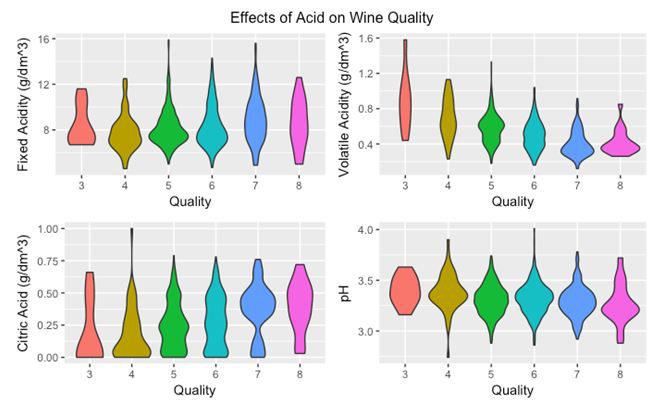
这是可视化酸效应的一种方式。随着Violin Plot横向扩展,表面在这些区域中有更多的数据点。
2. 特征可视化
在你生成特性后,如何看出一个预测的好坏。
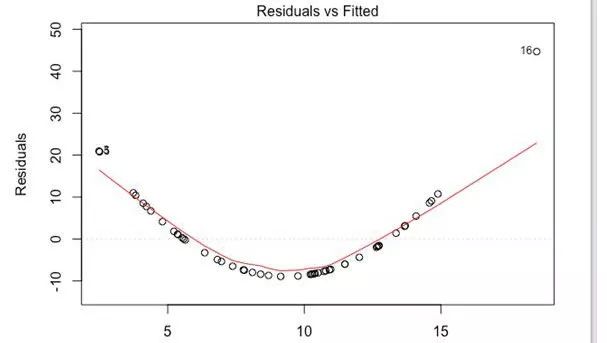
图表告诉我们,预测点离拟合线的距离。
另一个我们必须创建的视觉效果的例子是“主成分分析”(Principal Component Analysis)。如果您想深入了解PCA,可以阅读下面链接中的文章。
-
Practical Guide to Principal Component Analysis (PCA) in R & Python
https://www.analyticsvidhya.com/blog/2016/03/practical-guide-principal-component-analysis-python/
这是在Rstudio中的Iris数据集:
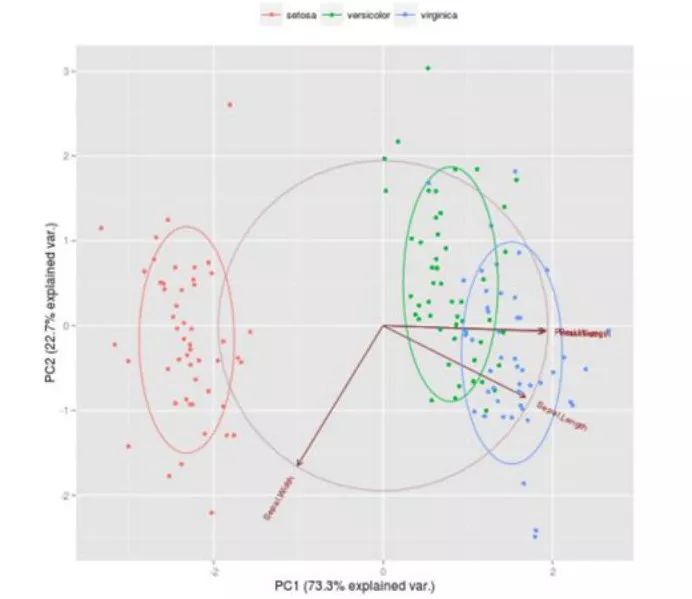
当我们对该数据集运行主成分分析时,会发现这些统计信息。

当我们绘制这个时,我们会发现视觉化结果比统计数据更具信息性。
3. 模型创建与比较
到了模型创建阶段,我们会发现需要了解数据的拟合方式。
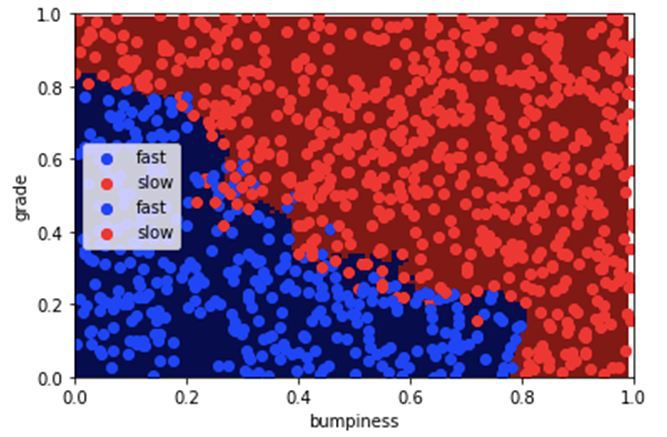
这是一个根据道路坡度和颠簸程度预测汽车该快还是慢的模型。
如你所见,决策边界清楚地对大多数数据进行了分类,但88.21%的准确率并不能说明问题。图中我们甚至可以看到错误分类的点离决策边界有多远。
我们可以通过查看决策边界来比较某些算法和技术。
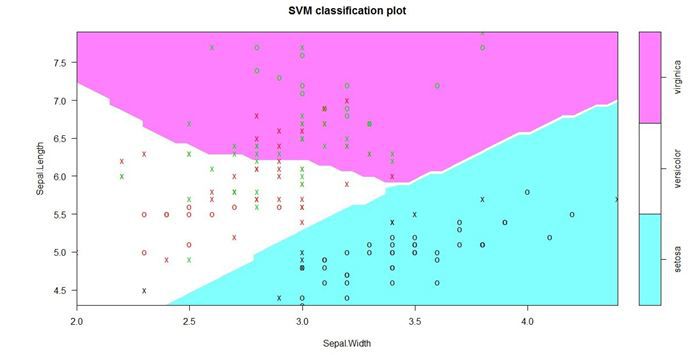
下面显示了使用Iris数据集的另一个示例:
这里没有太多信息来获取关于模型的有价值的见解。
想了解更多关于向量机的信息,可以阅读下面这篇文章:
-
Understanding Support Vector Machine algorithm from examples (along with code)
Understanding Support Vector Machine algorithm from examples (along with code)
另一方面,该图向我们展示了一个清晰的物种的分类边界。
五、讲故事的最佳实践
现在你已经知道可以用“讲故事”的方式来解释我们的观点,当你自己解决这个问题是,我将给你一些实用的提示:
- 始终在图中标记轴并给出绘图标题;
- 必要时使用图例;
- 使用眼睛看起来较浅并且比例适中的颜色;
- 避免添加不必要的细节,比如不具备良好可读性的背景或主题;
- 只有一个点可以根据水平和垂直位置同时编码两个定量值;
- 如何你正在进行时间序列的编码,不要使用点进行可视化。
六、结束语
讲故事的方式不仅仅是它的用法。它能帮你从你过去遗漏的数据中发掘新见解。数字永远无法清晰的描述特征和数据之间的关系,故事和图表将是很好的替代。
本文中我们已经详细阐述了故事是如何在各种途径中被使用的。从它们在模型构建步骤中的使用方式开始,我们逐渐了解哪些图表适合哪些特定的数据类型。
希望你读完这篇文章很开心。 期待听到你的数据故事!
原文标题:
The Art of Story Telling in Data Science and how to create data stories?
原文链接:
The Art of Story Telling in Data Science and how to create data stories?
来自:
更多阅读:
